2026年6月18日星期四 · 共 10 篇精选

编辑视角
‘聊天机器人’的时代已经正式落幕,我们正迈入‘智能体效能’的新纪元。今日的科技动态明确释放了一个信号:行业重心已从语言流畅度转向了硬核的执行力与环境探索。过去,百万级上下文是闭源模型的杀手锏,但 GLM-5.2 的发布彻底打破了这一垄断。通过 IndexShare 架构和 1M 长度的开源实现,大模型在长时程编程任务上的表现已逼近顶尖闭源水平。特别是其引入的‘努力程度控制系统’,标志着开发者对模型推理成本的管理正从‘黑盒调用’转向‘按需分配’。我们不再只是在对话框里提问,而是在编排能够处理复杂轨迹的数字员工。
然而,CEO-Bench 的模拟结果像一盆冷水,泼在了那些高喊‘AGI 已至’的人头上。即便是最强模型在面对 500 天的初创公司模拟经营时,也难以维持长期盈利。这揭露了当前架构的致命伤:‘规划与执行的断层’。写一段逻辑清晰的代码对模型来说已非难事,但在充满噪音的商业环境中,平衡定价、营销与现金流的连锁反应,仍让当前的 AI 显得力不从心。对工程师而言,这预示着未来的技术高地不再是单纯的参数规模,而在于如何让智能体在‘非结构化’的真实世界中具备更强的容错性与自我纠偏能力。
为了填补这一鸿沟,仅靠更聪明的模型是不够的,我们需要一套让 AI 主动探索世界的标准化协议。今天由微软、谷歌和 Hugging Face 联手推出的 Agentic Resource Discovery (ARD) 规范,堪称 AI 界的‘域名系统’(DNS)。它将智能体从死记硬背的工具定义中解放出来,转向基于意图的动态发现。如果一个智能体不能在运行时自主寻找所需资源,那它永远只是个高级脚本。开发者必须意识到,构建封闭、僵化的集成方案已无出路。未来的赢家将属于那些能够融入联邦式、可发现生态系统的开发者。基础设施正在加速补齐,而真正的‘商场实战’将是检验智能体成色的最终战场。
基础模型
基础模型作为生成式人工智能的核心架构,正朝着超长上下文和复杂任务执行能力快速演进。以 GLM-5.2 为代表的新一代模型,通过支持百万级上下文,显著提升了在长程任务和大规模代码理解中的表现。这些开源进展不仅深化了模型在专业领域的应用,也为构建具备高度自主性的智能体奠定了坚实的技术基础。
GLM-5.2 发布:具备 100 万上下文能力的开源长程任务大模型
IndexShare 在每四个稀疏注意力层中重用相同的索引器,在 1M 上下文长度下将每 token 的 FLOPs 降低了 2.9 倍。
在该基准测试中,GLM-5.2 仅落后 Opus 4.8 约 1%,同时领先 GPT-5.5 约 1% 以及 Opus 4.7 约 11%。
GLM-5.2 是一款专为长程任务设计的开源大模型,支持稳定的 100 万(1M)Token 上下文,并采用 MIT 开源协议。该模型引入了 IndexShare 架构,在 1M 上下文长度下可将每 Token 的 FLOPs 降低 2.9 倍,同时改进了 MTP 层使推测解码接收长度提升达 20%。在 FrontierSWE 评测中,GLM-5.2 的表现仅落后于 Opus 4.8 约 1%,并超越了 GPT-5.5。此外,模型新增了思维努力程度控制功能,允许用户在任务执行速度与计算成本之间进行权衡。作为目前性能最强的开源模型之一,它在 Terminal-Bench 2.1 等基准测试中大幅领先前代版本,显著缩小了与顶级闭源模型的差距。
AI 应用
AI 应用旨在展示人工智能如何从理论研究走向实际落地,深刻改变各行业的运作方式。本栏目聚焦 AI 在航天探测、医疗健康及智能制造等领域的具体实践,展示模型如何赋能硬件实现自主决策。通过视觉语言模型等前沿技术的跨领域应用,AI 正在成为解决复杂现实问题并提升生产效率的核心驱动力。
NAVI-Orbital:全球首个在轨零样本视觉语言模型实现自主地球观测
NAVI-Orbital 实现了据作者所知首次在轨视觉语言模型演示,在航天器上完全自主执行多模态推理
地面基准测试(在 7,960 张图像的 AID 基准测试中达到 88.16% 的准确率)
NAVI-Orbital 于 2026 年 4 月 16 日成功完成了全球首次在轨视觉语言模型演示,在低地球轨道航天器上实现了完全自主的多模态推理。该系统采用 Gemma 3 模型进行场景分类并生成自然语言描述,通过 LangGraph 编排检测与对话代理。地面基准测试显示其在 AID 数据集上达到了 88.16% 的准确率,且无需针对飞行仪器进行微调。操作员可以使用纯英文提示词而非传统指令序列对卫星进行任务重新分配。这种基于硬件加速 GPU 推理的技术实现了地球观测数据的“语义压缩”,有效解决了在轨数据采集与地面下行带宽限制之间的矛盾。
来源: arXiv cs.AI
AI 智能体
AI 智能体正从简单任务执行向具备长期决策和硬件集成能力的复杂系统演进。通过 CEO-Bench 等模拟框架,智能体展现了在长周期业务管理中的潜力,而资源发现标准的建立提升了其动态利用工具的能力。结合机器人工作流的优化,这些进展标志着智能体正逐步打通数字推理与物理执行的界限,迈向更自主且通用的生态系统。
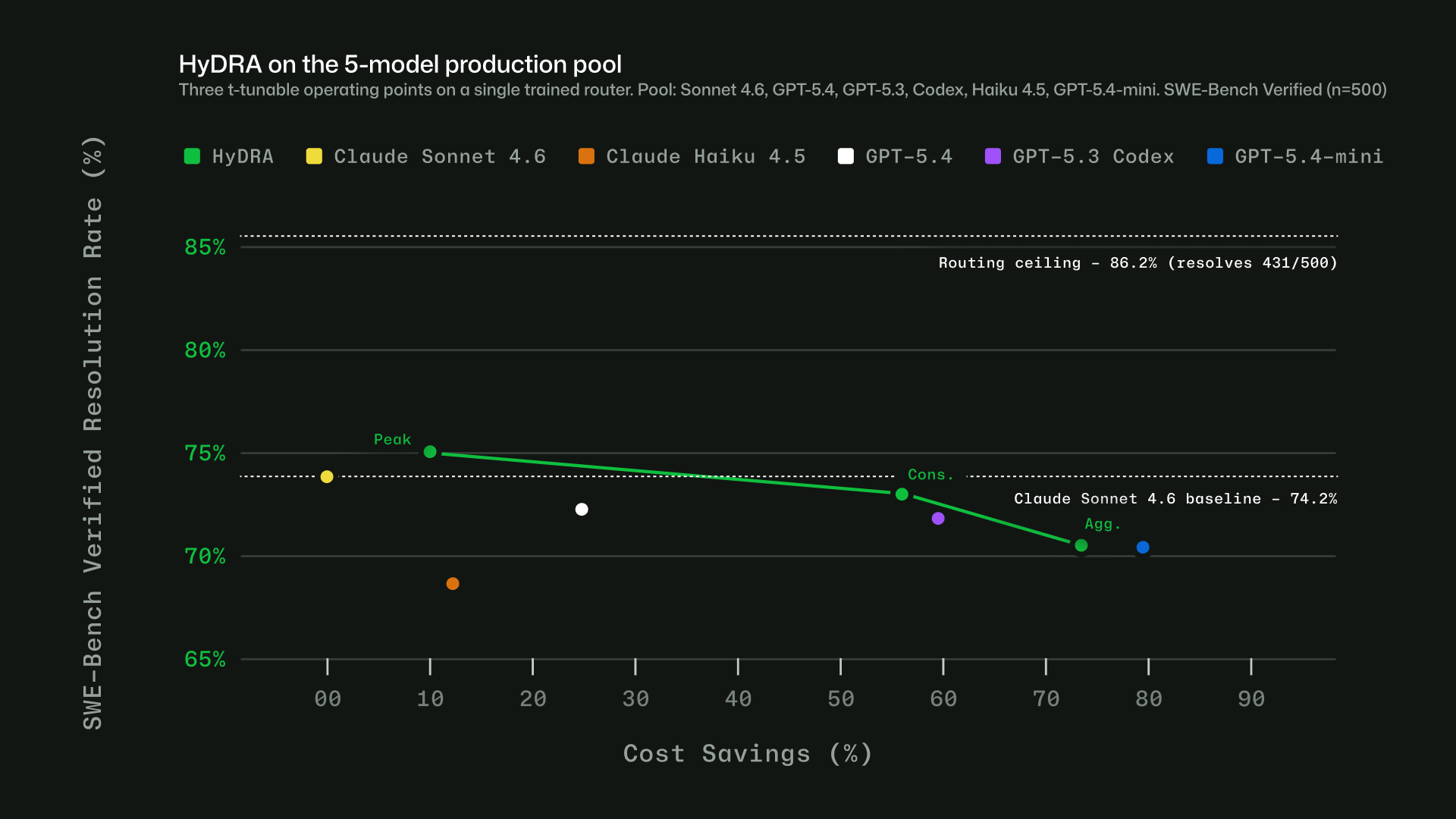
CEO-Bench:通过500天创业模拟评估AI智能体的长期决策能力
只有 Claude Opus 4.8 和 GPT-5.5 的最终余额超过了 100 万美元的初始资金,且两者都无法实现持续盈利。
CEO-Bench 通过模拟运营一家创业公司 500 天这一具有代表性的现实世界任务,来共同评估这些能力。
在CEO-Bench模拟测试中,仅有Claude Opus 4.8和GPT-5.5的最终余额超过了100万美元的初始资金,且两者均未能实现持续盈利。该基准测试通过Python接口模拟了为期500天的创业公司运营管理,要求智能体在噪声环境和不确定性中处理定价、营销及预算等任务。尽管顶尖模型能编写代码分析客户习惯并预测现金流,但大多数现有模型在协调多项决策以达成长期目标方面仍面临巨大挑战。这一研究标志着评估智能体在复杂现实任务中持续、适应性进展迈出了重要一步。
来源: arXiv cs.AI
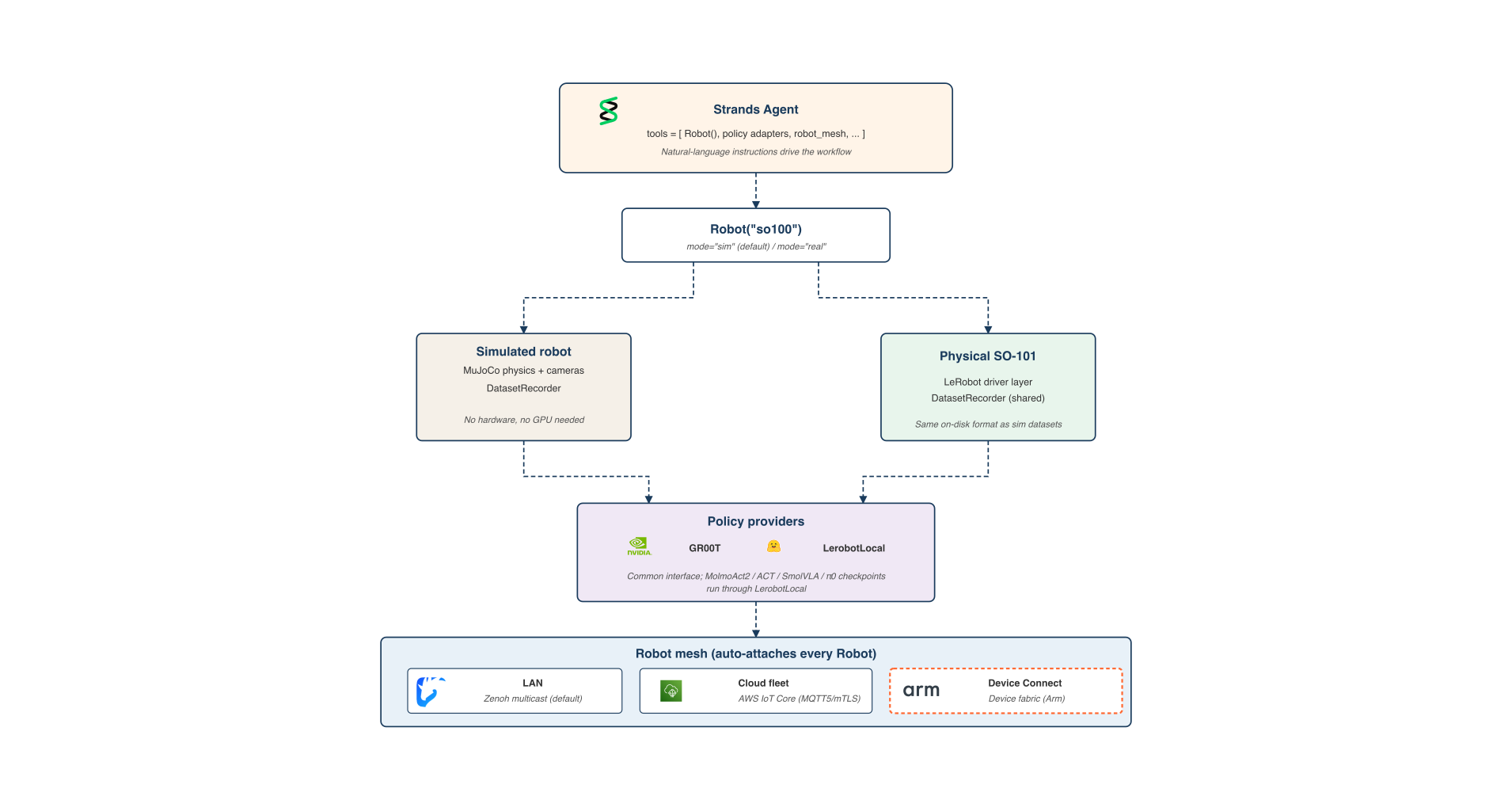
利用 Strands Agents 与 LeRobot 实现从 Hub 到硬件的机器人工作流集成
Strands Robots 是来自 AWS 的开源 SDK(Apache 2.0),它将机器人抽象、仿真和 LeRobot 堆栈公开为 AgentTools
仿真工具以与 LeRobot 在硬件上写入的相同格式记录 LeRobotDatasets。
AWS 推出的开源 SDK Strands Robots 将 LeRobot 堆栈整合为 AgentTools,通过单一代理循环简化了机器人开发流程。该框架解决了录制、训练、仿真、部署及协调需使用五种独立工具的碎片化问题。它采用统一的 LeRobotDataset 格式,确保仿真与实机数据在磁盘上完全兼容。系统支持 GR00T 和 LerobotLocal 进行策略推理,开发者只需更改一个关键字参数,即可将代码从 MuJoCo 仿真环境迁移至 SO-101 物理硬件。此外,该 SDK 集成了基于 Zenoh 的对等网络,可实现机器人集群的协同指挥。
智能体资源发现(ARD):动态 AI 工具集成的新标准
智能体资源发现(ARD)规范是位于它们前面的发现层。
这是一项草案级开放规范,由来自微软、谷歌、GoDaddy、Hugging Face 等公司的贡献者共同开发。
智能体资源发现(ARD)规范提供了一个开放的发现层,允许 AI 智能体在运行时动态查找工具、技能和其他智能体,而无需预先安装配置。该协议由微软、谷歌和 Hugging Face 等公司共同开发,解决了硬编码 MCP 服务器 URL 和上下文窗口限制带来的扩展性难题。通过利用发布者身份和合规性证明等丰富信号对功能进行索引,ARD 将生态系统从静态目录转变为基于意图的自然语言搜索。Hugging Face 已推出其参考实现工具 Discover,集成了数千个项目和 MCP 服务器。该规范定义了静态清单格式和动态注册表 API,以促进跨平台的联合发现。这一进展使智能体能够动态获取不断增长的服务资源,减轻了开发者的维护负担。

开发工具
本栏目聚焦软件开发环境的最新演进,涵盖从 AI 编程助手到自动化构建系统的各类工具。我们深入解析 GitHub Copilot 等平台如何通过优化上下文处理与模型路由来提升开发效率,助力工程师应对复杂的架构挑战。掌握前沿的调试工具、版本控制系统及集成开发套件,助您实时跟进提升代码质量与工程效率的关键技术动态。
GitHub Copilot 优化上下文处理与模型路由机制
Prompt 缓存帮助 Copilot 为重复的提示词前缀重用模型状态,而不是在每个请求中重新计算相同的前缀。
工具搜索允许模型按需加载工具定义,而不是在每一轮中将每个完整的工具架构都发送到上下文中。
GitHub Copilot 在 VS Code 中通过引入 Prompt 缓存和工具搜索功能,显著提升了长会话的 Token 使用效率。Prompt 缓存技术允许重用重复的前缀模型状态,减少了重复计算的开销。工具搜索功能则支持按需加载工具定义,避免了在每一轮对话中发送冗余的完整工具架构。与此同时,Auto 模型选择功能可根据任务意图和模型健康状况,自动为开发者匹配最合适的计算模型。该机制能够识别任务是否需要深度推理,从而在确保质量的前提下,灵活选择高性能或高效率模型。这些优化共同确保了 Copilot 在处理复杂多文件修改及调试任务时更加智能且经济。
来源: The GitHub Blog
研究论文
深入探索人工智能学术前沿,聚焦多模态推理与空间智能的突破性进展。本次收录的研究涵盖了MolmoMotion模型,其利用大规模数据集实现了精准的语言引导3D运动预测;同时关注CaVe-VLM-CoT框架,通过闭环验证机制显著提升了视觉语言模型的可解释性。这些论文展示了如何通过创新架构,不断拓展机器对人类意图的理解以及对物理世界认知的边界。
MolmoMotion:基于语言引导的3D运动预测模型与MolmoMotion-1M数据集
MolmoMotion-1M是最大的3D点轨迹与动作描述配对集合,提取自116万个视频。
MolmoMotion预测这些点在未来几秒钟内将在3D空间中移动到何处,其性能大幅优于现有的预测方法。
MolmoMotion-1M数据集包含116万个视频及其对应的3D点轨迹和动作描述,是目前该领域规模最大的开源数据集。基于此数据开发的MolmoMotion模型能够根据RGB图像和自然语言指令,预测物体在3D空间中的未来运动轨迹。该模型采用与类别无关且视角稳定的3D点表示法,在预测性能上显著优于现有方法,可直接用于机器人路径规划和可控视频生成等任务。此外,该项目还开源了包含2700个视频剪辑的人工验证基准测试PointMotionBench。这些工具和数据的发布,旨在将运动感知从回顾性观察推向具有物理合理性的前瞻性预测,为智能体交互研究提供基础支持。

CaVe-VLM-CoT:通过闭环验证增强视觉语言模型的可解释性
CaVe-VLM-CoT 在 ScienceQA 上实现了 87.1% 的准确率和 56.6% 的 CaVeScore
检测到的未证实主张会触发向提取器发送结构化反馈,以进行针对性重新检索
CaVe-VLM-CoT 在 ScienceQA 测试中达到了 87.1% 的准确率,并在 MMMU 基准测试中实现了 55.2% 的准确率。该框架通过由提取器、检索器、求解器、引文注入器和验证器组成的五阶段闭环流水线,强制执行基于证据的推理。系统能将检测到的未证实主张反馈给提取器进行针对性重新检索,从而有效减少视觉语言模型的幻觉问题。此外,该研究提出了包含 23 个组件指标的评价体系及综合指标 CaVeScore,用于衡量引文准确性与跨模态落地效果。这种模块化代理架构在不修改模型底层结构的情况下,显著提升了推理的可解释性与忠实度。
来源: arXiv cs.AI
编程技术
追踪编程领域的最新趋势,涵盖核心语言演进、开发工具优化及高效工程实践。本栏目深入探讨如 Git Worktrees 等进阶技巧,助力开发者提升并行开发效率并优化工作流。无论你是关注底层架构设计还是框架迭代,这里提供的技术见解都将帮助你构建更具健壮性和可扩展性的现代化软件系统。
Git Worktrees 指南:优化上下文切换与并行开发
Git 工作树自 2015 年以来一直存在,但直到最近才开始流行。
使用工作树,您永远不会离开分支,也永远不需要暂存,并且原始功能的工作区上下文将保持不变。
Git worktree 允许开发者在单个仓库下维护多个关联的工作目录,从而实现无需 git stash 或频繁切换即可同时处理多个分支。尽管该功能早在 2015 年便已推出,但近期因其能有效降低上下文切换的精神开销而受到广泛关注。通过为紧急修复等任务创建同级文件夹,开发者可以在保留原始编辑器环境的同时,在并行空间中进行操作。这种方法消除了暂存冲突的风险,并避免了在不同分支间反复安装依赖的繁琐过程。VS Code 等现代开发环境已提供完整支持,进一步降低了使用门槛。此外,AI 驱动的并行开发需求和日益盛行的“代码审查文化”也促使开发者更多地采用这种多任务并行的工作模式。
来源: The GitHub Blog
数据与分析
本栏目聚焦于数据管理与分析领域的最新进展,重点探讨企业如何利用 AI 驱动的规划工具和集成化平台实现数据基础设施的现代化。通过深入解析自动化迁移策略与云端数据架构优化,我们为您呈现提升数据流动性与洞察力的前沿方案,助力您在数字时代高效完成向智能化云环境的平滑过渡。
现代化 Azure 数据迁移:借助 AI 规划与集成工具实现平滑过渡
Azure Copilot Migration Agent 正在通过新的 Azure 存储集成扩展 Azure Migrate,目前已提供预览版。
Azure Storage Mover:用于文件/对象数据的免费、托管在线迁移和同步工具。
企业存储迁移不仅涉及数据复制,更关乎在处理 PB 级数据时保护业务连续性并维护系统性能。微软在 Azure Migrate 中心引入了 Azure Copilot Migration Agent 预览版,利用 AI 驱动的指导来简化存储迁移决策,改变了以往依赖零散脚本和第三方工具的现状。Azure Storage Mover 提供了受管的在线同步功能,而 Azure Data Box 则针对带宽受限的环境提供安全的离线传输方案。这些工具共同支持发现、评估及依赖项分析,确保数据能够无缝迁移至支持 AI 和分析的 Azure 架构中。通过集成的规划基础,企业可以更有效地管理成本并降低大型工作负载迁移中的中断风险。

本报告由 WindFlash AI 自动生成,内容基于过去 48 小时内的公开 AI 资讯。