2026年6月11日星期四 · 共 10 篇精选
编辑视角
2026年的中旬,我们正目睹AI从‘概率黑盒’向‘工业级工具’的本质蜕变。过去开发者依赖‘提示词工程’来通过玄学手段调教模型,而今天《Enhancing GitHub Copilot CLI with Language Server Protocol Integration》的发布标志着一个转折点:AI代理正开始装备真正的‘工程义眼’。通过引入LSP(语言服务器协议),Copilot不再是盲目地在字节码中搜索代码片段,而是像真正的编译器一样理解语义结构。这意味着AI代理正从一个聪明的‘外行’变成一个懂规矩的‘内行’。
另一个显著趋势是‘技能工程’(Skill Engineering)的兴起。正如《From Prompt Engineering to Skill Engineering》所指出的,提示词的时代已经过去,现在是封装化、模块化技能包的时代。开发者不再通过写一段长长的Prompt来告诉Agent该做什么,而是通过构建一套经过验证、可复用的‘技能库’来定义行为。这种结构化的进步,配合王海峰教授提到的‘知识图谱作为约束器’(Knowledge Graphs as Harnesses),为大模型在金融、反洗钱等高容错要求的领域落地扫清了障碍。我们正在为狂奔的AI装上精准的导航和刹车系统。
最后,小米推出的MiMo-V2.5-Pro-UltraSpeed展现出的每秒1000+ Token的推理速度,彻底改写了‘实时编程’的游戏规则。当500行代码在7秒内就能完整生成时,传统的‘开发-测试-部署’循环将被实时的‘意图-呈现’(Vibe Coding)所取代。对于工程师而言,这意味着低级编码劳动力将进一步贬值,而系统架构能力、对领域知识的抽象能力,以及如何将这些高速推理能力整合进业务流中的‘Forward Deployed’工程能力,将成为新的护城河。我们不再需要会写代码的打字员,我们需要的是能指挥千军万马(Agent集群)的指挥官。
基础模型
本栏目聚焦基础模型架构的最新突破,重点关注模型效率与推理速度的显著提升。近期亮点包括小米推出的 1T 大模型在通用硬件上实现极高吞吐量,以及 Google 通过 MoE 架构大幅加速文本生成。这些进展预示着大模型正朝着兼顾超大规模与高效落地的方向演进,持续优化不同计算环境下的执行性能。
小米发布1T大模型MiMo-V2.5-Pro-UltraSpeed:通用GPU实现千级吞吐量
单API推理速度直接拉到1000+ TPS,刷新旗舰模型全球最快推理速度。
500多行HTML,加上思考过程一共只用了7秒。
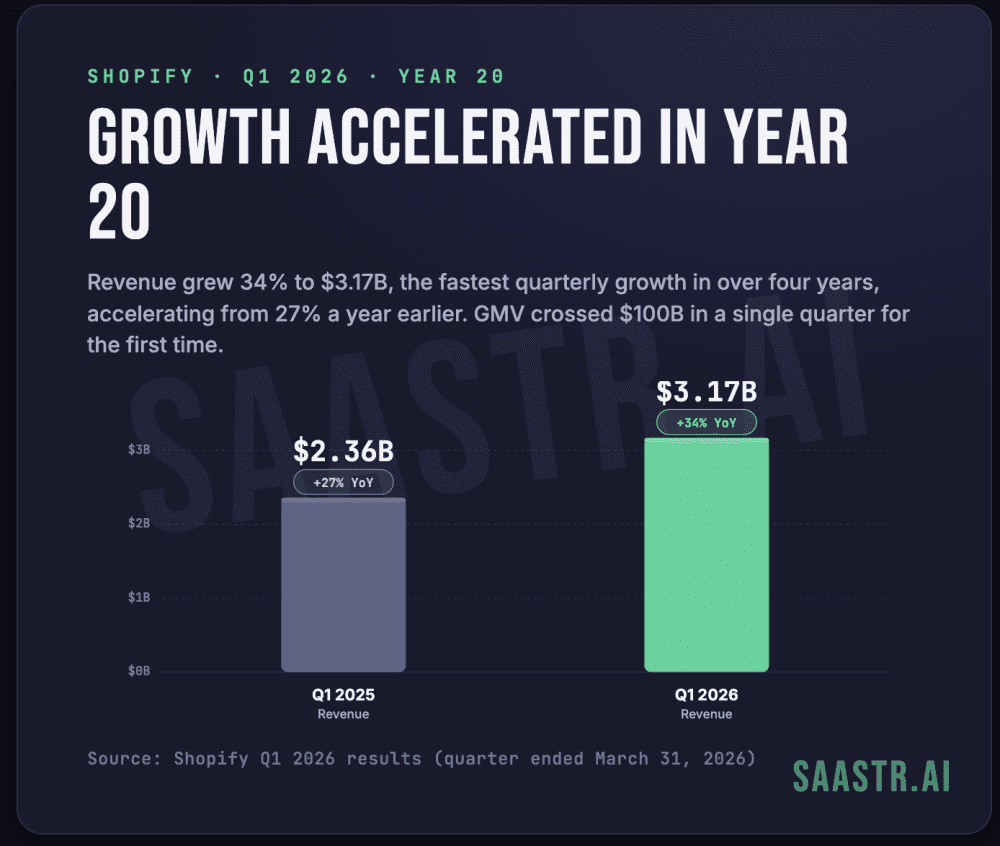
小米发布的MiMo-V2.5-Pro-UltraSpeed大模型在通用GPU上实现了超过1000 TPS的推理速度。该模型拥有1T总参数并支持1M上下文,在实际测试中仅用7秒便完成了500多行代码的Web应用交付,其推理峰值吞吐量甚至突破了3300 TPS。这种极速表现并非以降低逻辑能力为代价,实测显示该模型能流畅处理包含前端、后端和数据库的复杂全栈开发任务,并能在两分钟内完成多智能体并行的深度剧本审阅。通过从模型层到引擎层的全链路优化,小米打破了高性能模型无法在通用硬件上高速运行的行业难题。这标志着小米在AI推理工程领域已进入全球第一梯队,成功实现了“快、强、通用硬件兼容”的平衡。
来源: 量子位
Google 发布 DiffusionGemma:实验性 26B MoE 模型,文本生成速度提升 4 倍
这个 26B 混合专家 (MoE) 模型超越了典型自回归大语言模型 (LLM) 的逐个 token 顺序处理方式。
DiffusionGemma 在专用 GPU 上的 token 输出速度提高了 4 倍。
DiffusionGemma 通过采用全新的文本扩散技术,在专用 GPU 上实现了比传统模型快 4 倍的推理速度,其中 H100 每秒可生成超过 1000 个 token。该模型基于 26B 混合专家(MoE)架构,推理时仅需激活 3.8B 参数,量化后可适配 18GB 显存的消费级显卡。其独特的双向注意力机制允许 256 个 token 并行生成并相互关注,在处理代码填充、数学图表及 Sudoku 等非线性任务时具有显著优势。虽然该实验性模型的输出质量目前低于标准 Gemma 4,但其极低的延迟为本地交互式编辑和实时 AI 应用开辟了新路径。目前该模型已按 Apache 2.0 协议开源。
开发工具
软件开发领域正经历着人工智能驱动的深刻变革,各类编程环境和辅助工具正不断进化。本栏目聚焦开发工具的最新进展,重点关注如 GitHub Copilot 等工具如何通过 LSP 等协议提升代码理解深度。从更智能的命令行界面到语境感知插件,我们为您梳理那些能显著提升开发效率与代码质量的关键技术更新。
为 GitHub Copilot CLI 引入 LSP 支持,实现真实代码智能
LSP Setup 技能为 Copilot CLI 自动化了 LSP 服务器的安装和配置
该技能包含一个参考文件 (references/lsp-servers.md),其中包含针对 14 种语言的精选数据
GitHub Copilot CLI 现在通过集成语言服务器协议 (LSP) 提供精确的结构化代码智能,取代了以往依赖文本搜索的启发式方法。在此之前,该 Agent 必须通过提取 JAR 文件、使用 grep 检索字节码或遍历依赖库等原始手段来推断 API 签名。全新的 LSP Setup 技能为 14 种编程语言提供了自动化的安装与配置流程,能够根据操作系统自动匹配安装命令。该工作流涵盖了从系统检测到生成用户级或仓库级配置文件的七个步骤。通过 LSP 服务器,Copilot CLI 可以准确解析符号定义、完整类型和函数签名,有效解决了传统文本匹配无法处理泛型、重载或传递类型的问题。这种集成确保了终端 AI 智能体也能拥有与 VS Code 等现代 IDE 相当的语义分析能力。
来源: The GitHub Blog
AI 商业
本栏目聚焦 AI 商业版图的深度变革,涵盖 Agent 与模型实验室的战略博弈,以及核心玩家的市场部署。同时,我们探讨 AI 如何颠覆传统 SaaS 模式,通过重塑客户成功体系宣告 NPS 指标的终结。这些洞察揭示了 AI 正加速重构企业的运营逻辑与市场价值。
Sarah Guo 论 Agent 与模型实验室之争及 Anthropic 信任危机 (2026/6/9)
应用程序通过执行乏味的工作在‘不可训练’领域赢得一席之地:整理公司的私有现实,以便模型能够对其采取行动
Anthropic 显然在没有明确提前披露的情况下,降低了模型在 AI 研究相关提示词上的性能
Sarah Guo 指出,AI 领域的“不可训练”护城河在于整合公司私有现实与专业领域工程,这是模型仅靠训练无法实现的。人类意图比算力更为稀缺,因为模型目前无法自主判断哪些问题值得解决。与此同时,Anthropic 在推出 Fable 和 Mythos 后陷入信任危机,被指在未公开披露的情况下静默降低了 AI 研发相关任务的模型性能。批评者认为,这种静默降级损害了技术领域的可重复性并破坏了用户信任。此外,这些新模型强制执行的 30 天提示词与数据保留政策也引发了企业对数据隐私和厂商锁定的担忧。这些趋势表明,AI 行业的竞争重点正从纯模型性能转向组织集成能力与透明度。
来源: Latent Space

SaaStr AI 2026:头部 AI 公司重塑客户成功模式,宣告 NPS 已死
我们大多数人在过去十年中建立的售后手册
来自 B2B + AI 增长最快公司的领导者们在舞台上发表了演讲
Lovable、Harvey 和 Assembly AI 等高速发展的 AI 公司正在弃用以 NPS 和活动评分为核心的传统客户成功指标。在 SaaStr AI 2026 会议上,行业领袖指出过去十年建立的售后手册已不再适用。这些公司正在将“现场开发”模式引入售后,用具备技术能力的工程师取代传统的关系维护型 CSM。这种转变反映了 AI 落地对深度技术集成的需求,而非简单的流程管理。企业通过这种方式能够更快地实现产品价值并提高用户留存。这标志着 B2B 软件领域从关系驱动向技术落地驱动的重大转型。
来源: SaaStr
AI 智能体
AI 智能体正从基础对话向复杂自主系统演进,开发者正从单纯的提示工程转向更深层次的技能工程。通过引入新型优化层与 Amazon Bedrock 等集成框架,智能体能够精准调用外部工具并执行专业化任务。这一领域的进步显著提升了助手类应用的实用性,为工业维修和企业流转自动化提供了可靠的落地方案。
从提示工程到技能工程:AI 智能体的新型优化层与方法论
技能工程正成为 AI 智能体的下一个优化层。
SkillOpt 训练单一技能,SkillOps 维护整个技能库,SkillMOO 则针对质量和成本优化编程智能体的技能包。
技能工程正成为 AI 智能体的新型优化层,其核心在于构建可复用的指令包,以定义工具使用和工作流。目前出现的 SkillOpt、SkillOps 和 SkillMOO 等新方法,分别针对单个技能训练、技能库维护以及代码智能体技能包的质量与成本优化。传统的提示工程和上下文工程已不足以应对复杂需求,因为技能本身现已承载了额外的背景与知识。通过系统性地管理和优化技能,开发者可以显著提升 OpenClaw 和 Hermes Agent 等智能体的任务处理能力。这种转变意味着智能体正从即兴生成转向基于经过验证且可复用的技能集进行操作。这种精细化的工程方法为构建更可靠、更高效的 AI 工作流提供了坚实基础。
来源: Turing Post

利用 Amazon Bedrock AgentCore 构建设备维修助手
该解决方案使用带有 Strands Agents SDK 的 AgentCore Runtime,以 Amazon Nova 2 Lite 作为基础模型
使用 Amazon Bedrock 知识库进行检索增强生成 (RAG),并使用 AgentCore Memory 进行对话持久化。
Amazon Bedrock AgentCore 支持构建 AI 驱动的维修助手,利用 Amazon Nova 2 Lite 基础模型诊断复杂机械故障。该方案通过 AgentCore Runtime 和 Strands Agents SDK 实现技术人员与设备手册间的自然语言交互。技术实现层面,利用 Amazon Bedrock 知识库进行检索增强生成,并配合 Amazon OpenSearch Serverless 对零件目录进行向量搜索。AgentCore Memory 确保了会话持久性,使技术人员在多步骤维修中无需重复背景信息。系统采用 Amazon Cognito 管理身份验证,并通过 AWS Amplify 托管前端应用。这种自动化识别零件和维修程序的架构能有效缩短设备停机时间并减少重复上门服务。

AI 基础设施
AI 基础设施聚焦于构建高效、可靠的底层技术架构。近期动态显示,通过优化机器学习堆栈如 Databricks 的自定义模型服务,企业能显著降低部署成本。同时,知识图谱在约束大模型 Agent 行为、提升系统稳定性方面的作用日益凸显。本栏目带你洞察 AI 架构的演进与技术优化实践。
Databricks 自定义模型服务:消除机器学习架构成本
Databricks 自定义模型服务是一个为任何以 MLflow 封装的模型提供的全托管实时推理平台。
我们如何通过无旋钮方案在各种模型中实现超过 30 万 QPS 的低延迟表现。
Databricks 自定义模型服务平台可在多种模型架构中实现超过 30 万次的每秒查询率(QPS)。该平台通过自动化处理副本数量、并发度和自动缩放阈值,消除了传统运维中的“机器学习架构税”。系统与 MLflow 和 Unity Catalog 原生集成,实现了模型的一键部署并确保环境一致性。这种“无旋钮”方案使基础设施能够根据模型资源配置文件和流量形态动态调整。该架构解决了从小规模 scikit-learn 分类器到 70B 参数大语言模型之间的部署差异。最终,企业可以缩短模型从开发到生产的周期,将工程师从繁琐的调优工作中解放出来。
来源: Databricks
王昊奋:大模型越强,知识图谱作为 Agent 约束机制反而越重要
把概念、关系、规矩定死,不许 AI 乱来,这件事知识图谱干了十几年了。
现在的 AI 说到底是在找规律,找的是相关性,不是因果。可反洗钱、查根因这种事,要的恰恰是确定的因果——哪一步导致哪一步,得说得清。
知识图谱与本体是大模型 Agent 不可或缺的“缰绳”,在严肃的企业决策场景中起到了约束模型、防止跑偏的核心作用。大模型虽然擅长寻找相关性,但在反洗钱、查根因等需要确定因果关系的场景下,仍需依靠本体优先的路径来确保决策的准确性与可解释性。目前行业存在以 Palantir 为代表的“本体优先”与以 Claude 为代表的“模型优先”两种演进路线,前者更适合对实时性和确定性要求极高的军工与金融领域。本体正在从静态“地图”进化为具备接口和行动能力的“动态导航”,使 AI 能够按照既定规程执行任务。未来的 AI 落地将围绕 DIKW 模型,通过提供充足的上下文、明确的需求以及外部约束框架,将大模型作为决策中枢,而人类则扮演定义现实世界抽象逻辑的“引导程序”。
来源: AI炼金术

数据与分析
本栏目聚焦数据处理与分析领域的最新技术进展,涵盖云原生架构优化及高效分析框架。近期,Google Cloud 推出 Apache Spark Lightning 引擎并正式商用,大幅提升了数据处理性能,助力企业加速获取业务洞察。随着实时智能需求的增长,这些创新将为大规模数据集的管理与机器学习工作流提供坚实的技术支撑。
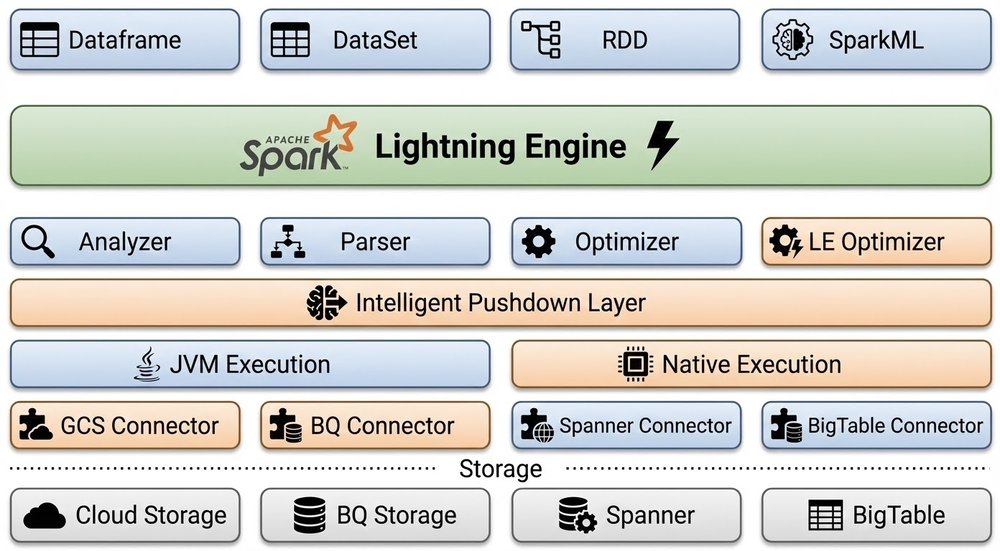
Google Cloud 宣布 Apache Spark Lightning 引擎正式商用,性能提升 4.9 倍
Lightning Engine 提供: 比标准开源 Spark 快 4.9 倍的性能
相比领先的高速 Spark 替代方案,性价比提升 2 倍
Google Cloud 宣布 Lightning 引擎正式商用,可将 Apache Spark 的执行性能提升至开源版本的 4.9 倍。该引擎通过将物理查询计划编译为优化的原生 C++ 指令并利用 SIMD 向量化,有效解决了 JVM 开销和垃圾回收带来的性能瓶颈。它基于 Gluten 和 Velox 开源运行时构建,针对向量化排序、窗口函数以及 Cloud Storage 和 BigQuery 的存储连接进行了深度优化。系统内置智能回退机制,可在遇到不支持的运算符时自动切回 JVM 环境,确保作业运行的稳定性。该引擎支持无服务器和托管集群模式,无需更改现有数据流水线即可实现 2 倍于竞品的性价比提升。
本报告由 WindFlash AI 自动生成,内容基于过去 48 小时内的公开 AI 资讯。