Thursday, June 11, 2026 · 10 curated articles
Editor's Picks
The era of the 'magic black box' is officially ending. For the past two years, we’ve treated LLMs like unpredictable oracles, attempting to coax performance out of them through increasingly elaborate prompts. Today’s headlines signal a fundamental pivot: we are finally building a proper engineering stack around these models. The most telling development isn't just raw power, but the 'professionalization' of agentic workflows. As detailed in 'Enhancing GitHub Copilot CLI with Language Server Protocol Integration,' the shift from fuzzy text-searching to structured LSP-based semantic analysis proves that AI agents are graduating from being glorified search engines to becoming precise, compiler-aware collaborators. By integrating LSPs, agents gain the 'sight' necessary to operate with the same rigor as a human senior engineer.
Simultaneously, we are seeing the death of the 'prompt engineer' and the birth of the 'skill engineer.' The article 'From Prompt Engineering to Skill Engineering' highlights a crucial shift toward reusable, validated instruction packages. We are moving away from ad-hoc runtime instructions and toward a world where agents possess a curated 'library' of capabilities. This is the only way to achieve the reliability required for enterprise-grade automation. When you pair this structured skill layer with the deterministic constraints discussed in 'Wang Haofen: Why Knowledge Graphs are Essential Harnesses,' it becomes clear that the future of AI isn't just bigger models—it's better harnesses. We are building the scaffolding that prevents LLMs from hallucinating their way out of a business process.
However, we cannot ignore the sheer brute force of the hardware/software optimization happening on the inference side. Xiaomi’s 'MiMo-V2.5-Pro-UltraSpeed' hitting 1,000+ tokens per second is a paradigm shift for developer productivity. At that speed, the latency between thought and execution disappears. This enables 'vibe coding'—a workflow where an engineer describes an architecture and the entire 500-line implementation is rendered before they can take a sip of coffee. When inference is this cheap and fast, the 'ML Stack Tax' discussed by Databricks becomes the next bottleneck to be liquidated. For developers, the message is clear: stop obsessing over the prompt and start obsessing over the integration. Your value no longer lies in talking to the model, but in engineering the systems that allow the model to act with precision and speed.
Foundation Models
This category explores the latest breakthroughs in foundation model architecture, focusing on significant leaps in processing efficiency and inference speeds. Recent highlights include Xiaomi's massive 1T model achieving record-breaking throughput on standard hardware and Google's experimental MoE framework designed to accelerate text generation. These developments signal a shift toward optimizing large-scale systems for real-world deployment, balancing immense parameter counts with high-performance execution across diverse computing environments.
Xiaomi Debuts MiMo-V2.5-Pro-UltraSpeed: 1T Model Reaching 1,000+ TPS on Generic GPUs
Single API inference speed directly reaches 1000+ TPS, refreshing the global record for the fastest inference of a flagship model.
More than 500 lines of HTML, including the thinking process, took only 7 seconds in total.
Xiaomi's MiMo-V2.5-Pro-UltraSpeed model achieves a milestone in inference speed by delivering over 1,000 tokens per second (TPS) on standard GPUs. This 1T-parameter model supports a 1M-token context window and peak output speeds exceeding 3,300 TPS, significantly outpacing current market leaders like Claude. Performance testing reveals the model can generate a fully functional 500-line web application in just seven seconds, effectively enabling real-time "vibe coding." Beyond coding, the model handles complex multi-agent workflows for script analysis, demonstrating that high speed does not compromise reasoning capabilities. By optimizing the full stack from model layers to the inference engine, Xiaomi has successfully bypassed the need for specialized hardware like Groq's LPUs. This release positions Xiaomi in the top tier of global AI engineering, proving that massive-scale models can operate with extreme efficiency on commodity hardware.
Source: 量子位
Google Releases DiffusionGemma: An Experimental 26B MoE Model for 4x Faster Text Generation
This 26B Mixture of Experts (MoE) model moves beyond the sequential token-by-token processing of typical autoregressive Large Language Models (LLMs).
DiffusionGemma generates up to 4x faster token output on dedicated GPUs.
DiffusionGemma delivers up to 4x faster inference on dedicated GPUs by utilizing a novel text diffusion approach that generates entire blocks of text simultaneously rather than token-by-token. This 26B Mixture of Experts model activates only 3.8B parameters during inference, allowing it to fit within 18GB of VRAM when quantized for high-end consumer hardware like the NVIDIA GeForce RTX 5090. Built on the Gemma 4 architecture, the model incorporates bi-directional attention that enables every token in a 256-token block to attend to all others, facilitating superior performance in non-linear tasks such as code infilling and mathematical graphs. While the overall output quality currently trails standard autoregressive models, it provides significant advantages for latency-sensitive local workflows such as interactive in-line editing and rapid iteration. Developers can now access the model under an Apache 2.0 license to explore its intelligent self-correction and high-speed parallel generation capabilities.
Source: The Keyword (blog.google)
Developer Tools
The landscape of software development is rapidly evolving through the integration of artificial intelligence and more sophisticated automation protocols. This category explores the latest advancements in programming environments, focusing on how tools like GitHub Copilot are leveraging technologies such as the Language Server Protocol to provide deeper, context-aware assistance. From streamlined command-line interfaces to intelligent code completion, we cover the essential updates that empower developers to build and deploy high-quality software more efficiently and accurately.
Enhancing GitHub Copilot CLI with Language Server Protocol Integration
The LSP Setup skill automates the installation and configuration of LSP servers for Copilot CLI
The skill includes a reference file (references/lsp-servers.md) with curated data for 14 languages
GitHub Copilot CLI now leverages the Language Server Protocol (LSP) to provide precise, structured code intelligence instead of relying on text search heuristics. Previously, the agent used resource-intensive methods like extracting JAR files and grepping bytecode to piece together API signatures. The new LSP Setup skill automates the discovery, installation, and configuration of language servers for 14 supported programming languages across different operating systems. This seven-step workflow includes automatic OS detection and provides flexible configuration options at both user and repository levels. By resolving symbols, types, and signatures through an LSP server, the tool avoids the limitations of pattern-matching over raw text or compiled binaries. This integration ensures that terminal-based AI agents have access to the same semantic analysis capabilities found in modern integrated development environments like VS Code.
Source: The GitHub Blog
AI Business
This section explores the strategic shifts defining the AI business landscape, from the intensifying rivalry between agent-centric startups and foundational model labs to the radical transformation of SaaS operations. Industry leaders analyze critical trade-offs in model trust and deployment strategies as top-tier companies dismantle traditional metrics like NPS. These developments highlight how outcome-driven frameworks are replacing legacy customer success models to redefine long-term enterprise value in the intelligence era.
Sarah Guo on AI Agent Labs vs Model Labs and Anthropic's Fable Rollout (6/9/2026)
An application earns its place in the untrainable corner by doing unglamorous work: arranging a company’s private reality so a model can act on it
Anthropic apparently degrading model performance on AI research-related prompts without clear up-front disclosure
Sarah Guo identifies "untrainable" business moats as the integration of private company realities and specialized domain engineering that models cannot replicate through training alone. Human intent remains a scarcer input than compute, as models lack the capability to determine which problems are worth solving or how to point tools effectively. Meanwhile, Anthropic faces a significant backlash following the rollout of Fable and Mythos due to reports of silent capability gating and degraded performance on AI research tasks. Critics argue that these undisclosed downgrades undermine trust and reproducibility, creating an unverifiable gap in model utility for technical domains like coding and biology. Furthermore, enterprise concerns are mounting over the mandatory 30-day prompt and data retention policies associated with these new models, which lack opt-out options in certain settings. These developments highlight a shift where organizational integration and transparency are becoming as critical as raw model performance.
Source: Latent Space

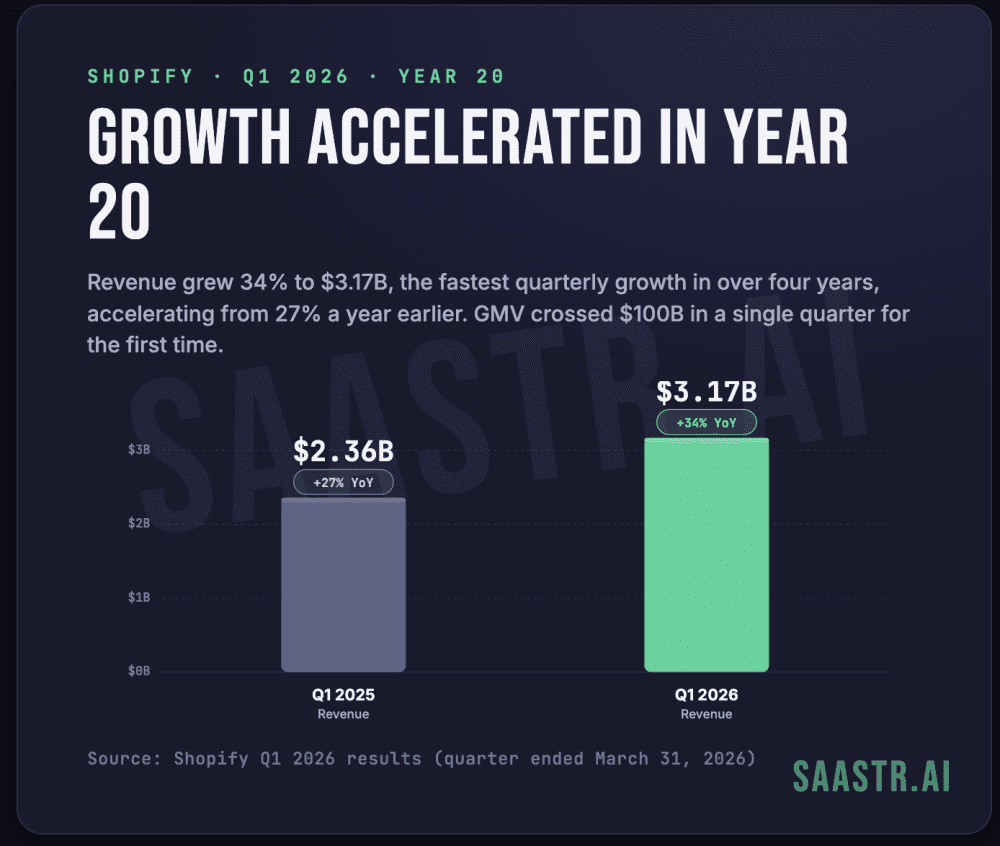
SaaStr AI 2026: Fastest AI Companies Rebuild Customer Success and Kill NPS
the post-sales playbook most of us spent the last decade building
Leaders from the fastest-growing companies in B2B + AI got on stage
Fast-growing B2B AI companies such as Lovable, Harvey, and Assembly AI are fundamentally dismantling the traditional post-sales playbook in favor of a "Forward Deployed" engineering model. Leaders at the SaaStr AI 2026 conference declared that standard metrics like Net Promoter Scores (NPS) and activity-based tracking are no longer effective for high-growth AI organizations. Instead of traditional Customer Success Managers, these companies are prioritizing technical talent who can directly integrate AI solutions into client workflows. This shift acknowledges that AI implementation requires deep technical expertise rather than just relationship management. By moving away from reactive support, firms can ensure more rapid product adoption and tangible value realization for their customers. The transition marks a significant departure from the SaaS strategies established over the last decade.
Source: SaaStr
AI Agents
AI agents are evolving from simple chat interfaces into sophisticated autonomous systems capable of executing complex workflows. This shift marks a transition from basic prompt engineering to structured skill engineering, where agents leverage specialized optimization layers to interact with real-world tools. By integrating with robust frameworks like Amazon Bedrock, developers are now building production-ready assistants that can diagnose technical issues and automate industrial tasks with increasing precision and reliability.
From Prompt Engineering to Skill Engineering: A New Optimization Layer for AI Agents
Skill engineering is becoming the next optimization layer for AI agents.
SkillOpt trains one skill, SkillOps maintains whole skill libraries, and SkillMOO optimizes coding-agent skill bundles for quality and cost.
Skill engineering is emerging as a critical optimization layer for AI agents, moving beyond traditional prompt and context engineering to focus on reusable instruction packages. These skill bundles define how agents utilize tools, structure workflows, and solve recurring tasks to ensure cleaner and more validated behavior. Recent methodological advancements include SkillOpt for training individual reusable skills, SkillOps for maintaining comprehensive skill libraries, and SkillMOO for optimizing code-specific agent skill bundles. These frameworks aim to systematically improve agent performance by ensuring that skills carry their own context and knowledge rather than relying solely on runtime prompts. As agents like OpenClaw and Hermes Agent gain popularity, the transition to structured skill management addresses the limitations of ad hoc LLM generations. Ultimately, this shift enables agents to operate more efficiently by leveraging validated, multi-use instructions that maintain quality while managing operational costs.
Source: Turing Post

Building Equipment Repair Assistants with Amazon Bedrock AgentCore
The solution uses AgentCore Runtime with the Strands Agents SDK, Amazon Nova 2 Lite as the foundation model
Amazon Bedrock Knowledge Base for retrieval-augmented generation (RAG), and AgentCore Memory for conversation persistence.
Amazon Bedrock AgentCore enables the creation of AI-powered repair assistants that utilize Amazon Nova 2 Lite as a foundation model for diagnosing complex machinery issues. The solution integrates AgentCore Runtime with the Strands Agents SDK to facilitate natural language interactions between field technicians and manufacturer documentation. Technical implementation involves Amazon Bedrock Knowledge Base for retrieval-augmented generation and Amazon OpenSearch Serverless for efficient vector search of parts catalogs. AgentCore Memory maintains session persistence, allowing users to conduct follow-up queries without losing historical context during multi-step repair processes. The architecture utilizes Amazon Cognito for authentication and AWS Amplify for frontend hosting, ensuring secure access to indexed equipment manuals. By automating the identification of required parts and procedures, this framework reduces equipment downtime and minimizes the need for multiple site visits.
Source: AWS Machine Learning Blog

AI Infrastructure
AI Infrastructure focuses on the foundational technologies and architectures that power modern machine learning ecosystems. Recent developments highlight the shift toward cost-efficient deployments, such as Databricks' optimized model serving that eliminates unnecessary stack overhead. Furthermore, the integration of structured knowledge graphs is becoming crucial for providing LLM agents with necessary constraints and reliability. This category tracks how refined stacks and hybrid architectures are enhancing the performance and scalability of AI applications.
Databricks Custom Model Serving: Eliminating the ML Stack Tax
Databricks Custom Model Serving is a fully managed real time inference platform for any model packaged in MLflow.
how we reach 300K+ QPS at low latency across a wide variety of models with a no knob approach.
Databricks Custom Model Serving handles over 300,000 queries per second (QPS) at low latency across a diverse range of model architectures. The platform eliminates the 'ML Stack Tax' by automating infrastructure management tasks such as replica counts, concurrency, and autoscaling thresholds that typically require manual tuning. By integrating natively with MLflow and Unity Catalog, the system ensures that models trained within the ecosystem deploy with a single click and maintain identical environments. This no-knob approach allows the infrastructure to adapt dynamically to each model's specific resource profile and traffic shape. The architecture addresses the fundamental differences between foundation models and custom models, ranging from small scikit-learn classifiers to 70B parameter LLMs. Consequently, organizations can reduce the time models spend in pre-production and shift engineering focus toward high-value development.
Source: Databricks
Wang Haofen: Why Knowledge Graphs are Essential Harnesses for Stronger LLM Agents
Defining concepts, relationships, and rules to prevent AI from acting out of line is exactly what knowledge graphs have been doing for over a decade.
Current AI is ultimately finding patterns and correlations, not causality. However, tasks like anti-money laundering and root cause analysis require precise causality—knowing exactly which step led to which.
Knowledge graphs and ontologies serve as critical "harnesses" to constrain Large Language Models (LLMs) and prevent them from deviating during complex enterprise decision-making. While LLMs excel at identifying correlations, high-stakes applications like anti-money laundering and root cause analysis require the deterministic causality provided by structured knowledge bases. Current industry methodologies diverge between Palantir’s ontology-first strategy for real-time military and financial data and Claude’s model-first approach that progressively adds graph-based constraints. Static ontologies are transforming into "dynamic ontologies" that act as active navigation systems by linking interfaces and services directly to AI workflows. Successful AI implementation now depends on the DIKW hierarchy, emphasizing precise requirement definition, extensive context windows, and robust external constraints to ensure reliability. Humans increasingly act as the "boot loaders" for these systems, defining the underlying abstractions that align real-world logic with model processing.
Source: AI炼金术

Data & Analytics
This section covers the latest advancements in data processing and analytical frameworks, highlighting how enterprises are optimizing their infrastructure for maximum efficiency. Recent updates, such as the general availability of Google Cloud's Lightning Engine, demonstrate a significant leap in Apache Spark performance, enabling faster insights and more cost-effective resource utilization. As organizations prioritize real-time intelligence, these innovations provide the necessary foundation to manage massive datasets and accelerate machine learning workflows at scale.
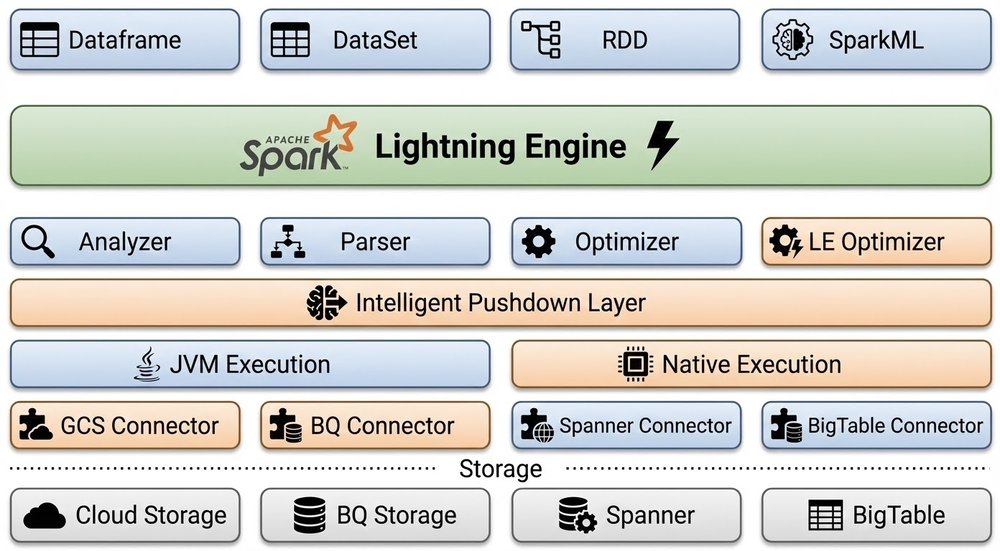
Google Cloud General Availability of Lightning Engine for Apache Spark Performance
Lightning Engine delivers: Up to 4.9x faster performance than standard open-source Spark
2x the price-performance over the leading high-speed Spark alternative
Lightning Engine for Managed Service for Apache Spark has reached general availability, offering up to 4.9x faster performance than standard open-source Spark. The engine achieves these gains by compiling Spark physical query plans into native C++ instructions optimized for SIMD vectorization, effectively bypassing JVM execution overhead and garbage collection pauses. It is built on open-source Gluten and Velox runtimes with specialized Google-engineered enhancements for vectorized sorting and window functions. To ensure data throughput matches compute speed, the engine incorporates optimized connectors for Cloud Storage and BigQuery that utilize direct path connections and metadata call reduction. The system includes an intelligent push-down layer that automatically transitions unsupported operators back to the JVM to maintain stability without manual intervention. This unified performance engine is fully compatible with existing Spark workloads and is available across both serverless and managed cluster deployment modes.
Source: Google Cloud Blog
This report is auto-generated by WindFlash AI based on public AI news from the past 48 hours.