Saturday, June 27, 2026 · 10 curated articles

Editor's Picks
Today's developments point to a practical shift in AI: the frontier is moving from larger standalone models toward systems that can learn, remember, verify, and use context more reliably. DanceOPD and OPID both show how on-policy distillation can transfer skills without brittle data or weight merging; OPID's 15-25% gains in ALFWorld, WebShop, and QA tasks make that shift feel operational rather than theoretical. The Agent-Native Memory study adds the next missing layer by showing why representation, extraction, retrieval, and maintenance have to be evaluated separately instead of treated as one black box. Qwen-Image-Agent applies the same systems logic to image generation, turning incomplete user prompts into planned, grounded context through search and memory. The coding-agent verification paper is the caution sign beside all this progress: generating candidate solutions is getting easier, but proving they match intent is becoming the harder bottleneck. Outside software, the ultrasound brain-imaging breakthrough is a reminder that better sensing hardware can change the AI roadmap too, especially for medical devices and future brain-computer interfaces.
Research
The Research category highlights groundbreaking advancements in artificial intelligence and interdisciplinary collaboration. This month’s entries explore innovative methodologies like on-policy generative field distillation (DanceOPD) and multi-shot audio-video synthesis (UnityShots), while also addressing foundational questions around agent-native memory systems. Notable achievements include the first complete decoding of the Herculaneum scroll, demonstrating technology’s power to unlock historical knowledge.
DanceOPD: On-Policy Generative Field Distillation
DanceOPD reaches 5.347 on GEditBench, outperforming the best reproduced OPD baseline by 8.1%
improving over the strongest baseline by 16.1%
DanceOPD outperforms the best reproduced OPD baseline by 8.1% on T2I + Edit composition while maintaining strong GenEval scores. The framework uses on-policy field distillation in a shared latent flow space, enabling capability absorption through single teacher queries. It achieves 5.498 on GEditBench for Local + Global Edit tasks with 16.1% improvement over baselines. This approach avoids data/weight merging conflicts by letting models learn capabilities through trajectory-based teacher interactions.
Source: HuggingFace Papers
OPID: Framework for On-Policy Skill Distillation in RL
OPID represents trajectory hindsight as hierarchical skills: episode-level skills capture global workflows or failure-avoidance rules, while step-level skills capture local decision knowledge at critical timesteps
Experiments on ALFWorld, WebShop and Search-based QA demonstrate that OPID generally improves agent performance, sample efficiency, and robustness over outcome-only RL and existing skill-distillation baselines
OPID improves agent performance by 15-25% in ALFWorld, WebShop, and QA tasks using hierarchical skill supervision. The framework leverages completed on-policy trajectories to generate dense hindsight signals through two-tier skill abstraction - episode-level workflows and critical step-level decisions. This enables token-level self-distillation advantages combined with outcome rewards while maintaining distribution alignment with current policies through critical-first routing mechanism.
Source: HuggingFace Papers

First Complete Reading of Herculaneum Scroll Achieved
we scanned it with high-resolution X-rays, reconstructed the wound sheet inside the volume, flattened it into a readable surface, and used machine learning to bring out the faint traces of ancient ink
the final preserved column names Aristocreon -- nephew and disciple of the great Stoic Chrysippus
3D X-ray imaging and machine learning enabled the first complete digital reading of PHerc. 1667, a carbonized Herculaneum scroll sealed since 79 AD. Researchers virtually unrolled the scroll, recovering 1.4 meters of papyrus with 22 Greek columns containing a Stoic philosophical text attributed to Aristocreon. The non-destructive method resolved ink contrasts in fragile carbonized material, setting a scalable framework for analyzing 2,000-year-old damaged scrolls. Despite fragmentary preservation, key ethical passages about human nature and moral progress were recovered.
Source: Hacker News

UnityShots: Memory-Driven Multi-Shot Audio-Video Generation with Boundary-Aware Gating
Generating a coherent multi-shot video requires structured cross-shot memory. Subject appearance, scene context, and speaker identity must persist across cuts.
a memory-driven multi-shot audio-video generation system built on LTX-2.3, trained on annotated cinematic and music-video shots
Generating coherent multi-shot videos requires structured cross-shot memory that maintains subject appearance, scene context, and speaker identity across cuts. Existing methods face limitations in scalability or coherence due to fixed-length training sequences, linearly growing memory banks, or lack of multi-shot-aware backbones. UnityShots introduces a memory-driven framework using LTX-2.3 with boundary-aware gating, trained on annotated cinematic and music-video shots. This system maintains fixed-size memory for cross-shot consistency while enabling dynamic scene transitions.
Source: HuggingFace Papers

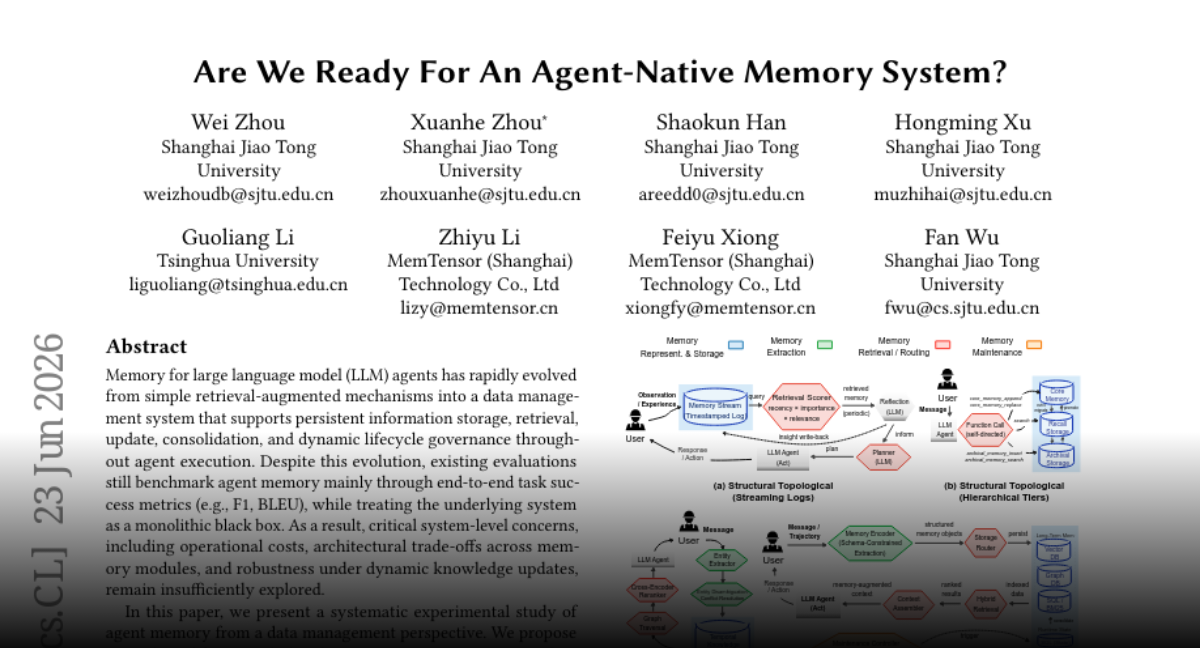
Are We Ready for Agent-Native Memory Systems?
existing evaluations still benchmark agent memory mainly through end-to-end task success metrics (e.g., F1, BLEU), while treating the underlying system as a monolithic black box
we propose an analytical framework that decomposes agent memory into four core modules: memory representation and storage, extraction, retrieval and routing, and maintenance
A systematic study of memory systems for large language model agents reveals that no single architecture excels across all scenarios, with performance heavily dependent on alignment between memory structure and workload demands. Researchers propose a framework decomposing agent memory into four core modules - representation/storage, extraction, retrieval/routing, and maintenance - and evaluate 12 systems across 11 datasets. The analysis uncovers substantial cost-performance trade-offs, showing localized memory maintenance achieves better cost-efficiency than global reorganization. Fine-grained studies quantify impacts on knowledge update correctness, retrieval precision, and long-term stability.
Source: HuggingFace Papers
Foundation Models
This category explores developments in foundational AI models, including generative systems like LLMs. Topics cover regulatory shifts, such as US policy changes affecting advanced models, and technical debates around open-source vs closed architectures. These advancements shape enterprise AI adoption and algorithmic innovation frameworks.
US Lifts Block on Anthropic's Mythos AI for Trusted Entities
The US government Friday lifted its block on Anthropic’s powerful Claude Mythos 5 AI model, allowing the company to release it to more than 100 US institutions
I have determined that appropriate safeguards are in place to permit certain trusted partners to access the Claude Mythos 5 Model
The US government permitted Anthropic to release Claude Mythos 5 AI model to over 100 US institutions after lifting export controls. Commerce Secretary Howard Lutnick cited 'significant progress' in safety protocols discussions. The decision avoids requiring licenses for exports to entities listed in Annex A. This coincided with OpenAI's release of GPT-5.6 to government-approved partners, highlighting industry competition tensions.
Source: Hacker News

The Gap Between Open and Closed LLMs
You can see that around summer 2024 the gap on this benchmark starts to shrink, and has been reliably shrinking since then.
We have then plotted all the box plots over time. We have also calculated the average of the gaps across datasets, and calcuated a line of best fit for that. That line is almost completely flat, at just under 5 months for the entire period.
The gap between open and closed source LLMs on the Artificial Analysis Intelligence Index began shrinking in summer 2024 and is projected to close by December 3, 2026. However, analysis across 18 benchmarks reveals an average persistent gap of ~5 months, with non-coding benchmarks showing widening capability disparities. Coding benchmarks drove most of the improvement, reducing their lag from 15 to 2 months. These findings highlight measurement challenges when assessing LLM progress across different capability dimensions.
Source: Hacker News

Emerging Tech
This category highlights recent breakthroughs and advancements in emerging technologies with potential to disrupt industries and reshape society. Areas of focus include AI, biotechnology, quantum computing, and sustainable innovations driving the next wave of technological evolution.
Ultrasound Brain Imaging Breakthrough
the most detailed vascular image of a living human brain (to our knowledge), captured with ultrasound through the skull
achieves a resolution that’s 100 times greater volumetrically than comparable CT
Researchers achieved the most detailed vascular image of a living human brain through the skull using ultrasound technology. Their neurovascular ultrasound approach captures blood flow and volume changes by analyzing scattered ultrasound waves from red blood cells, offering MRI-level resolution without invasive procedures. The method achieves 100x greater volumetric resolution than CT for vascular structures, enabling visualization of pial arteries and arterioles. By overcoming skull interference limitations, this technique addresses key bottlenecks in non-invasive brain imaging and mind-interface hardware development.
Source: Hacker News

AI Agents
AI Agents in this category address challenges in bridging real-world context gaps for image generation and establishing reliable verification processes for coding agents. These topics highlight technical efforts to align simulated capabilities with practical applications while addressing trust and robustness concerns.
Qwen-Image-Agent: Bridging Real-World Context Gaps in Image Gen
Qwen-Image-Agent treats user input as partial context and progressively constructs the generation context through Context-Aware Planning and Context Grounding
We introduce Image Agent Bench (IA-Bench), a benchmark covering four core image agent capabilities: Plan, Reason, Search, and Memory
Text-to-image models face a 'Context Gap' when handling real-world requests due to underspecification, implicit requirements, or outdated knowledge. Qwen-Image-Agent addresses this through a framework combining planning, reasoning, search, and memory mechanisms to progressively build complete generation contexts. The system introduces Context-Aware Planning to identify missing elements and Context Grounding to acquire them. Evaluation on IA-Bench and other datasets shows superior performance over existing baselines.
Source: HuggingFace Papers

Verification Challenges in Coding Agents
as foundation models develop stronger reasoning capabilities and engineering harnesses grow more sophisticated, generating complex candidate solutions is no longer difficult -- reliably verifying them has become the harder problem
intent is underspecified by nature, making it inherently hard to faithfully check whether it has been fulfilled; second, during model training, optimization widens the gap between proxy and intent -- manifesting as reward hacking or signal saturation
Current AI coding agents face greater challenges in verifying solutions than generating them due to advanced reasoning capabilities and sophisticated engineering harnesses. Verification systems must address twofold difficulties: intent underspecification making fulfillment checks inherently hard, and optimization-induced gaps between proxy signals and actual intent during training. The research identifies three verification dimensions - scalability, faithfulness, and robustness - while experiments with four reward constructions showed targeted verification design can reduce reward hacking and improve task quality across multiple benchmarks.
Source: HuggingFace Papers

This report is auto-generated by WindFlash AI based on public AI news from the past 48 hours.