Friday, June 26, 2026 · 10 curated articles
Editor's Picks
The era of the 'monolithic model' is rapidly collapsing, replaced by a sophisticated, modular architecture where performance is a product of orchestrated subsystems rather than raw parameter count. We see this shift clearly in 'Evaluating Agent-Native Memory Systems,' where the industry is finally moving past the naive assumption that a model’s context window is sufficient for intelligence. By decomposing memory into representation, extraction, and maintenance, developers are acknowledging that an agent is only as good as its data retrieval strategy. This is not just a software pattern; it is a fundamental shift toward agentic engineering that prioritizes operational efficiency over brute-force scaling.
We are also seeing the democratization of this modularity through platforms like Oxlo.ai, which treats frontier models as interchangeable utility components rather than walled gardens. For engineers, this is a massive win. When you couple this infrastructure with tools like BrowserAct—which finally bridges the gap between static LLM reasoning and the messy, dynamic reality of the web—you realize we are entering a phase where 'system integration' is the primary challenge. The goal is no longer just to build a model; it is to build a reliable harness that can steer, observe, and sustain an agent’s operation over time.
However, the excitement of these architectural advancements shouldn't blind us to the 'black box' problem, both technical and ideological. As our study on political bias indicates, the discrepancy between stated model neutrality and output reality is a latent bug that we haven't yet learned to debug. Relying on these systems for decision-making is perilous when the internal logic remains opaque. If we are to build truly 'autonomous' systems—like the ones proposed in 'Ask, Solve, Generate' that evolve through internal feedback loops—we must demand more granular interpretability. Engineers shouldn't just be building these pipelines; they must be building the diagnostic tools that hold them accountable. The future isn't just about faster inference or bigger models; it’s about the rigor of the framework supporting them.
AI Agents
This category explores the evolution of AI agents, focusing on the architectural innovations powering autonomous task execution. We analyze the technical rigor behind agent-native memory systems, evaluating how data management strategies impact long-term context retention and reasoning. Furthermore, we examine industry-standard benchmarks for agentic frameworks, providing critical insights into the performance, efficiency, and real-world reliability of tools like GitHub Copilot as they transition from passive coding assistants to proactive, self-directed agents.
Evaluating Agent-Native Memory Systems: A Data Management Perspective
no single architecture dominates across all scenarios; instead, effectiveness depends heavily on how well the memory structure aligns with the workload bottleneck.
existing evaluations still benchmark agent memory mainly through end-to-end task success metrics (e.g., F1, BLEU), while treating the underlying system as a monolithic black box.
Systematic evaluation of 12 memory systems across five workloads reveals that no single architecture dominates agent-native performance across all scenarios. Existing benchmarks often treat memory as a monolithic black box, obscuring critical architectural trade-offs and operational costs associated with information storage and retrieval. An analytical framework proposed by the researchers decomposes memory into four core modules: representation, extraction, retrieval, and maintenance. Fine-grained ablation studies demonstrate that localized maintenance strategies offer significantly higher cost-efficiency compared to global reorganization processes. These findings highlight that performance effectiveness depends heavily on aligning specific memory structures with unique workload bottlenecks during agent execution. By quantifying impacts on representation fidelity and long-horizon stability, the study provides a roadmap for developing more robust, cost-effective agent memory frameworks.
Source: HuggingFace Papers
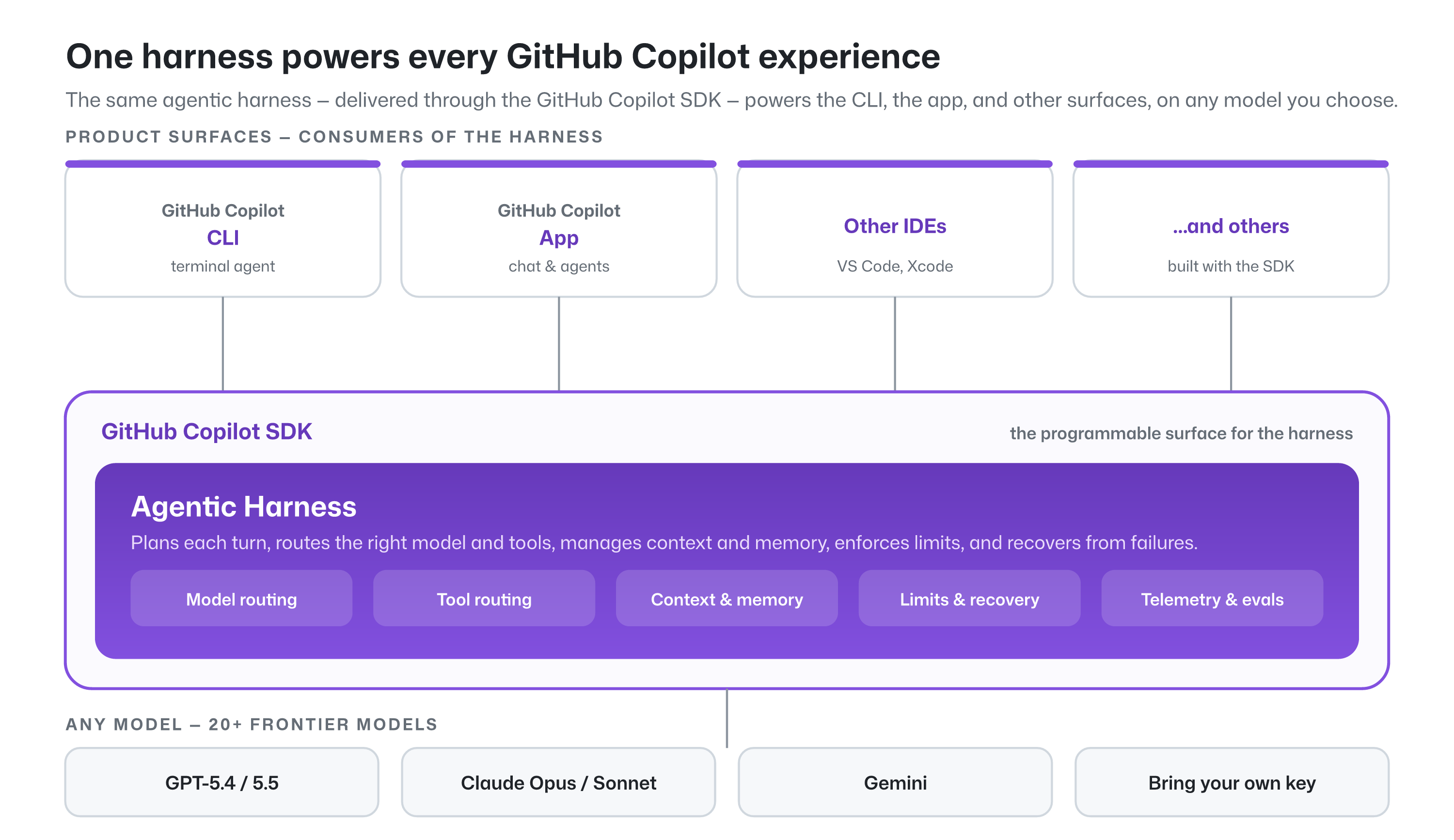
Evaluating GitHub Copilot Agentic Harness Performance and Efficiency
The GitHub Copilot agentic harness delivers strong results across multiple benchmarks and leading token efficiency, while maintaining flexibility to choose among more than 20 models.
GitHub Copilot's agentic harness achieves strong performance results across multiple industry benchmarks while maintaining high token efficiency. This architecture provides the flexibility to integrate and evaluate more than 20 different AI models, allowing developers to optimize for specific project requirements. By testing diverse models, the framework demonstrates that effective agentic workflows rely on balancing computational overhead with task accuracy. The research highlights the importance of modularity in building scalable AI systems for software engineering. Future developments in this space will likely focus on further reducing latency and enhancing reasoning capabilities for complex programming tasks. This evaluation provides a structured approach for practitioners to benchmark agentic behaviors in real-world development environments.
Source: The GitHub Blog
AI Policy & Ethics
This category examines the evolving landscape of global AI governance, legislative frameworks, and the critical ethical challenges surrounding automated systems. We analyze how policy decisions impact innovation, accountability, and the responsible deployment of emerging technologies. By scrutinizing political biases and regulatory standards, we provide insights into how institutions are shaping the future of artificial intelligence to ensure alignment with human values and societal safety.
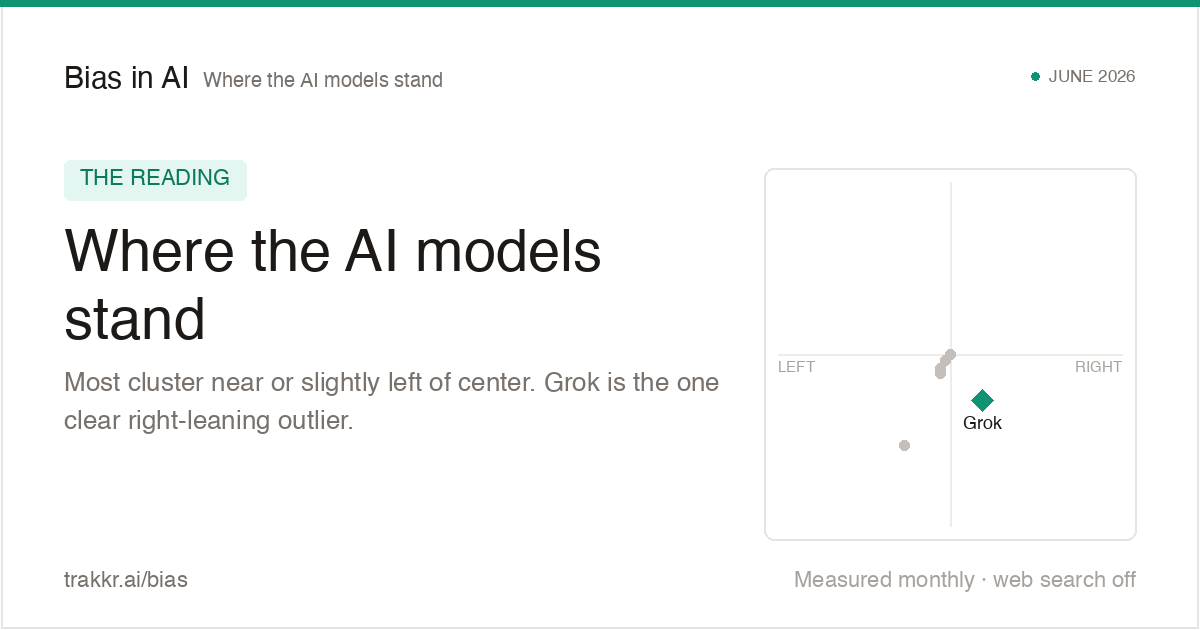
Mapping Political Bias in Major AI Models
4 of 6 models lean left of center.
The hollow mark is what the model says when asked which way it leans; the solid mark is where it actually measured on the economic axis
Four out of six major AI models exhibit a measurable left-of-center political leaning according to a comprehensive study involving 4,400 query responses. The research utilizes a dual-axis mapping system—economic and social—to visualize how models like Grok, Gemini, and Claude position themselves when responding to charged questions about politics, economics, and society. Findings reveal that while several models claim neutrality when self-assessing, their actual performance data indicates consistent ideological drifts compared to their stated stances. For example, ChatGPT and Llama lean left despite claims of neutrality, while Grok is identified as the furthest right-leaning model in the set. This data serves as a critical indicator of how AI transparency impacts user perception, as millions of individuals increasingly rely on these systems for political and civic information. The analysis highlights the gap between developer-stated objectives and the internal biases manifest in real-world model outputs.
Source: Hacker News
Research
This section covers the latest breakthroughs in academic research, spanning computer vision, multimodal intelligence, and neuroscience. We highlight significant papers that push the boundaries of current technology, from advanced video diffusion distillation techniques to innovative AI-driven methods for decoding complex biological processes. Stay informed on the foundational science and novel frameworks driving the next generation of technological innovation.
First Full Reading of a Herculaneum Scroll via Virtual Unwrapping
PHerc. 1667, sealed since the eruption of Vesuvius in 79 AD, has been virtually unwrapped and read from beginning to end.
We have completely virtually unwrapped and read PHerc. 1667 — the scroll the Vesuvius Challenge community knows as Scroll 4 — without ever touching its pages.
PHerc. 1667, a carbonized scroll sealed since the 79 AD eruption of Mount Vesuvius, has been successfully read in full using non-invasive virtual unwrapping techniques. Researchers achieved this milestone by employing high-resolution X-ray scanning to reconstruct the internal layers of the papyrus without physically opening the fragile artifact. Machine learning algorithms were subsequently used to detect and enhance faint traces of ancient ink on the flattened surface, revealing twenty-two columns of Stoic philosophical text. This breakthrough provides a scalable methodology for recovering contents from hundreds of other sealed rolls that were previously deemed too delicate to handle. The recovered sections discuss human nature and ethics, offering new insights into ancient scholarly traditions. By combining advanced imaging with computational analysis, this project transforms historical preservation and opens a long-lost library to contemporary academic study.
Source: Hacker News

Causal-rCM: Advancing Autoregressive Diffusion Distillation for Streaming Video
Notably, our distilled 2-step causal Wan2.1-1.3B model achieves a VBench-T2V score of 84.63 with only 1 or 2 sampling steps.
we present the first implementation of teacher-forcing-based continuous-time CMs (e.g., sCM/MeanFlow) for autoregressive video diffusion, enabled by our custom-mask FlashAttention-2 JVP kernel, achieving 10times faster convergence compared to discrete-time CMs
The distilled 2-step causal Wan2.1-1.3B model achieves a VBench-T2V score of 84.63, demonstrating the efficacy of the newly introduced Causal-rCM framework. This methodology extends rCM to autoregressive video diffusion by combining teacher-forcing for stable initialization and self-forcing for on-policy refinement. The researchers implemented continuous-time consistency models utilizing a custom-mask FlashAttention-2 JVP kernel, which accelerates convergence by 10 times compared to traditional discrete-time approaches. Causal-rCM serves as a unified, scalable recipe for diffusion distillation, enabling both frame-wise and chunk-wise streaming video generation. Its application to the Cosmos 3 foundation model showcases its potential for building action-conditioned interactive world models. By relying exclusively on synthetic training data, this advancement highlights a significant shift toward efficient, high-performance video generation pipelines.
Source: HuggingFace Papers

DanceOPD: On-Policy Generative Field Distillation for Unified Image Generation
Modern image generation demands a single model that unifies diverse capabilities, including text-to-image (T2I), local editing, and global editing.
we introduce DanceOPD, an on-policy generative field distillation framework for flow-matching models that routes each samp
DanceOPD introduces an on-policy generative field distillation framework specifically designed to resolve alignment conflicts in flow-matching image generation models. Modern image generation models frequently suffer from degraded text-to-image performance when incorporating specialized local and global editing capabilities. This new framework effectively mitigates these performance trade-offs by routing samples through a specialized distillation process that harmonizes competing generation tasks. Researchers can now integrate diverse capabilities without the traditional degradation seen in multi-functional model training. The approach serves as a novel solution for training unified architectures that require simultaneous proficiency in text-driven synthesis and pixel-level editing. Ultimately, this methodology enhances model stability and performance consistency across various generative requirements.
Source: ArXiv
Ask, Solve, Generate: Autonomous Self-Evolving Multimodal Models
Most unified large multimodal models (LMMs) that support both visual understanding and image generation still rely on curated post-training supervision
We propose a self-evolving training framework with three internal roles: a Proposer that generates visual questions, a Solver that answers and evaluates them, and a Generator that synthesizes images.
Unified large multimodal models can now enhance both visual understanding and image generation capabilities autonomously by leveraging unlabeled image data. This self-evolving framework employs a tripartite architecture consisting of a Proposer, a Solver, and a Generator to create a closed-loop training cycle. Proposers formulate visual queries, while Solvers provide evaluation and answers, and Generators synthesize corresponding imagery to refine performance. By utilizing internal self-consistency signals rather than human-curated preference labels or external supervision, the system significantly reduces dependence on costly post-training datasets. The proposed methodology offers a path toward scalable multimodal development that thrives on raw data rather than manual annotations. This approach demonstrates a novel way to align vision and generation tasks through iterative feedback loops.
Source: ArXiv
Using AI-Driven Causal Testing to Decode Brain Language Processing
Researchers introduce generative causal testing, which translates black box models into clear hypotheses and verifies them in the scanner, revealing what specific brain regions respond to in language.
Generative causal testing allows researchers to translate black-box AI models into actionable hypotheses that are directly verifiable through brain imaging. This methodology successfully identifies the specific stimuli and linguistic features that trigger responses in targeted neural regions during cognitive tasks. By bridging the gap between computational model performance and neurobiological observation, the approach transforms complex AI outputs into interpretable biological insights. The technique represents a significant shift in how neuroscientists can systematically interrogate the mechanisms of the human brain using artificial intelligence. Future applications may include mapping more complex cognitive functions by leveraging these automated hypothesis-generation pipelines. This framework effectively refines the understanding of how language is represented at a granular level within the cerebral cortex.
Source: Microsoft Research Blog (current)
AI Infrastructure
AI infrastructure focuses on the foundational hardware, cloud compute, and software frameworks that power generative models. This category highlights the tools, APIs, and platforms enabling developers to scale, deploy, and manage high-performance AI workflows efficiently. By bridging the gap between raw computing power and practical application, these solutions are essential for building the next generation of intelligent systems.
Oxlo.ai: Access 35+ Frontier AI Models via a Unified API
Access 35+ frontier AI models including DeepSeek V4 Pro, Kimi K2.6, GLM 5, Qwen, Llama, and Mistral through a single API.
Scale across AI models with predictable monthly subscriptions, benchmark-grade performance, generous usage limits, and we never train on your data.
Oxlo.ai provides unified access to more than 35 frontier AI models including DeepSeek V4 Pro, Kimi K2.6, GLM 5, Qwen, Llama, and Mistral through a single API endpoint. This platform addresses the common industry struggle where development teams often select models without adequate visibility into eventual operational costs. By offering predictable monthly subscription tiers, it allows companies to benchmark performance across different providers while strictly adhering to data privacy standards that prohibit model training on user inputs. The infrastructure enables developers to compare responses and calibrate individual model usage for specific tasks, effectively optimizing workflows without scaling bills linearly with usage. By centralizing model management, the service simplifies the integration process for engineering teams who require flexibility and cost control in their LLM-driven applications. This approach helps shift the paradigm from model-first development to performance-based model selection strategies.
Source: Product Hunt
Developer Tools
Developer tools are the essential building blocks that empower engineers to build, test, and deploy software more efficiently. This category highlights the latest advancements in programming frameworks, IDE extensions, and automation utilities designed to streamline complex development workflows. Stay updated on the cutting-edge solutions that help developers bridge the gap between architectural concepts and functional production code.
BrowserAct: Specialized Browser Automation for AI Agents
BrowserAct is built for agents using the web. It gives agents a browser layer for real websites, so they can pass blocked pages, adapt to real scenarios, run multiple tasks safely, and return clean web data for reasoning.
BrowserAct provides a dedicated browser layer designed to facilitate complex web interactions for AI agents. The tool enables agents to navigate blocked pages, adapt to dynamic real-world scenarios, and execute multi-step tasks within a secure, controlled environment. By streamlining processes such as form filling, file uploads, and handling authentication, it allows agents to return clean, structured web data for further reasoning. This solution addresses the specific technical challenges of browser-based automation, ensuring that agents can reliably operate on real websites without frequent disruptions. It represents a significant advancement for developers building autonomous systems that require deep web integration and repeatable workflow capabilities.
Source: Product Hunt
This report is auto-generated by WindFlash AI based on public AI news from the past 48 hours.