Thursday, June 25, 2026 · 10 curated articles

Editor's Picks
The era of the 'black box' model is giving way to the era of the 'orchestrated agent.' Today's headlines—ranging from the industrial-scale model distillation reported in Anthropic's clash with Alibaba to the specialized infrastructure for browser automation like BrowserAct—signal a profound shift in how we build. Developers are no longer just wrapping API calls; they are architecting complex, multi-modal systems where memory, context, and external action take center stage. When Anthropic flags 28.8 million exchanges used to 'distill' Claude, it’s not just a story about IP theft; it’s a reality check on the commoditization of intelligence. We are moving toward a future where a foundation model’s value is increasingly determined by its ability to play nice with other software, rather than its raw parameter count.
The real disruption lies in the maturation of the agentic stack. Projects like OpenKnowledge and the analytical rigor seen in the research on agent-native memory systems suggest that the industry is finally moving beyond the 'chatbot' phase. We are solving the fundamental engineering bottlenecks—latency, memory retention, and context grounding. As we see in the evaluation of GitHub Copilot’s agentic harness, the future isn't a single 'god-model' that does everything; it is a heterogeneous environment where developers mix and match models based on cost, speed, and reasoning requirements. This decoupling of intelligence from infrastructure is the defining trend of 2026.
For engineers, this means the barrier to building high-value, autonomous software has never been lower, but the complexity of managing these systems has never been higher. You aren't just shipping code anymore; you are shipping stateful, persistent, and self-updating intelligence. Whether it’s integrating disparate data via Zaro or managing browser-based interactions, the 'agentic harness' is the new middleware. The winners in this market won't necessarily be the ones with the best weights, but the ones who build the most resilient connective tissue between their data, their models, and the real world. We are in the middle of a gold rush, and the developers building the shovels—the memory frameworks, the browser layers, and the data classification pipelines—are the ones who will ultimately own the infrastructure of the next decade.
AI Policy & Ethics
This category tracks the evolving landscape of global AI governance, data privacy standards, and corporate accountability. We monitor key legal battles, regulatory policy shifts, and ethical dilemmas arising from the rapid deployment of large language models. Stay informed on how major technology firms navigate intellectual property disputes and international compliance frameworks in an increasingly scrutinized industry.
Anthropic Accuses Alibaba of Illicitly Extracting Claude AI Model Capabilities
Anthropic said the campaign was conducted between April 22 and June 5, 2026, and generated more than 28.8 million exchanges with Claude through almost 25,000 fraudulent accounts.
The strike by Alibaba is described as a "distillation" effort, which Anthropic has said involves training a less capable model on the outputs of a stronger one.
Anthropic revealed that Alibaba illicitly extracted Claude AI model capabilities through over 28.8 million exchanges using nearly 25,000 fraudulent accounts between April and June 2026. This large-scale campaign utilized a distillation method, where a less capable model is trained on the outputs of a stronger one to accelerate the development of advanced domestic AI capabilities. The findings were detailed in a formal letter sent to U.S. Senate Banking Committee leaders, marking one of the most significant intellectual property disputes in the sector to date. This incident follows prior warnings from Anthropic regarding similar extraction efforts by other Chinese firms, including DeepSeek and Moonshot AI. Anthropic continues to advocate for coordinated industry and policy responses to mitigate the rising intensity and sophistication of these unauthorized data collection campaigns, which pose ongoing national security and competitive risks to U.S. AI laboratories.
Source: Hacker News
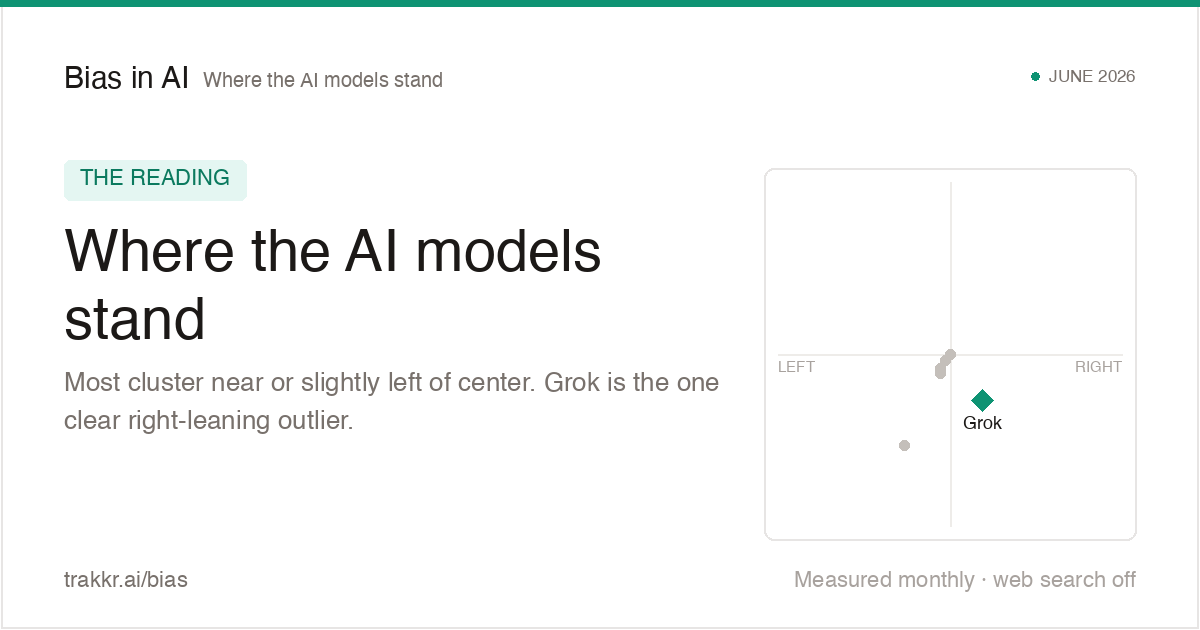
Mapping Political Bias in Major AI Models: June 2026 Analysis
4 of 6 models lean left of center.
The hollow mark is what the model says when asked which way it leans; the solid mark is where it actually measured on the economic axis
Four out of six major AI models lean to the left of center according to a June 2026 evaluation built from 4,400 responses. The study maps model behavior across economic and social axes, then compares measured output against each model's self-described neutrality. ChatGPT and Llama claim neutral positioning while their answers measure left of center, while Grok appears as the clearest right-leaning outlier. The finding matters because millions of users now ask AI systems for help interpreting news, politics, and social questions. The gap between declared neutrality and measured behavior turns model bias into a product trust issue, not just an academic debate. It also explains why bias charts like this spread quickly through developer and policy circles: they make a usually invisible alignment problem visually legible.
Source: Hacker News
AI Agents
This section focuses on the tools and system patterns turning AI from passive chat into active software. Today's stories highlight agent memory, browser automation, and contextual app-building as the practical layers developers are debating and adopting in public.
Evaluating Agent-Native Memory Systems: A Data Management Perspective
no single architecture dominates across all scenarios; instead, effectiveness depends heavily on how well the memory structure aligns with the workload bottleneck.
localized maintenance is more cost-efficient than global reorganization.
Experimental analysis of 12 memory systems reveals that no single architecture dominates across all scenarios, as effectiveness depends heavily on aligning memory structures with workload bottlenecks. This study decomposes agent memory into four core modules—representation and storage, extraction, retrieval and routing, and maintenance—to move beyond monolithic evaluation approaches. Findings demonstrate that localized maintenance strategies are significantly more cost-efficient than global reorganization methods in realistic agent execution environments. The research provides a comprehensive analytical framework for developers to quantify individual effects on representation fidelity, retrieval precision, and long-horizon stability. Moving forward, the paper identifies specific architectural trade-offs that practitioners must navigate to build truly agent-native systems. By shifting focus from end-to-end metrics like F1 or BLEU, the findings highlight critical system-level concerns essential for the future development of robust, scalable LLM agent memory architectures.
Source: HuggingFace Papers
BrowserAct: Specialized Browser Automation for AI Agents
It gives agents a browser layer for real websites, so they can pass blocked pages, adapt to real scenarios, run multiple tasks safely, and return clean web data for reasoning.
BrowserAct provides a dedicated browser layer designed specifically for AI agents to interact with real-world websites more effectively. The platform enables agents to navigate blocked pages, adapt to complex dynamic scenarios, execute multiple tasks simultaneously, and output clean data for reasoning. By offering robust handling for clicks, form fills, file uploads, and authenticated sessions, it addresses the common friction points that currently limit agentic web browsing capabilities. This infrastructure allows developers to integrate persistent browser workflows into their existing models, ensuring that agents can perform repeatable, reliable actions across various web environments. Its specialized feature set is built to help overcome typical hurdles such as verification challenges and site-specific navigation hurdles, ultimately enhancing the operational reliability of autonomous web agents in professional production environments.
Source: Product Hunt
Developer Tools
This section covers the latest advancements in developer environments, automation agents, and productivity software. We explore how emerging AI-driven tools are optimizing coding workflows and documentation management to help engineers build software more efficiently. From large-scale performance benchmarking of agentic frameworks to new open-source editors, these updates highlight the essential utilities transforming modern development practices.
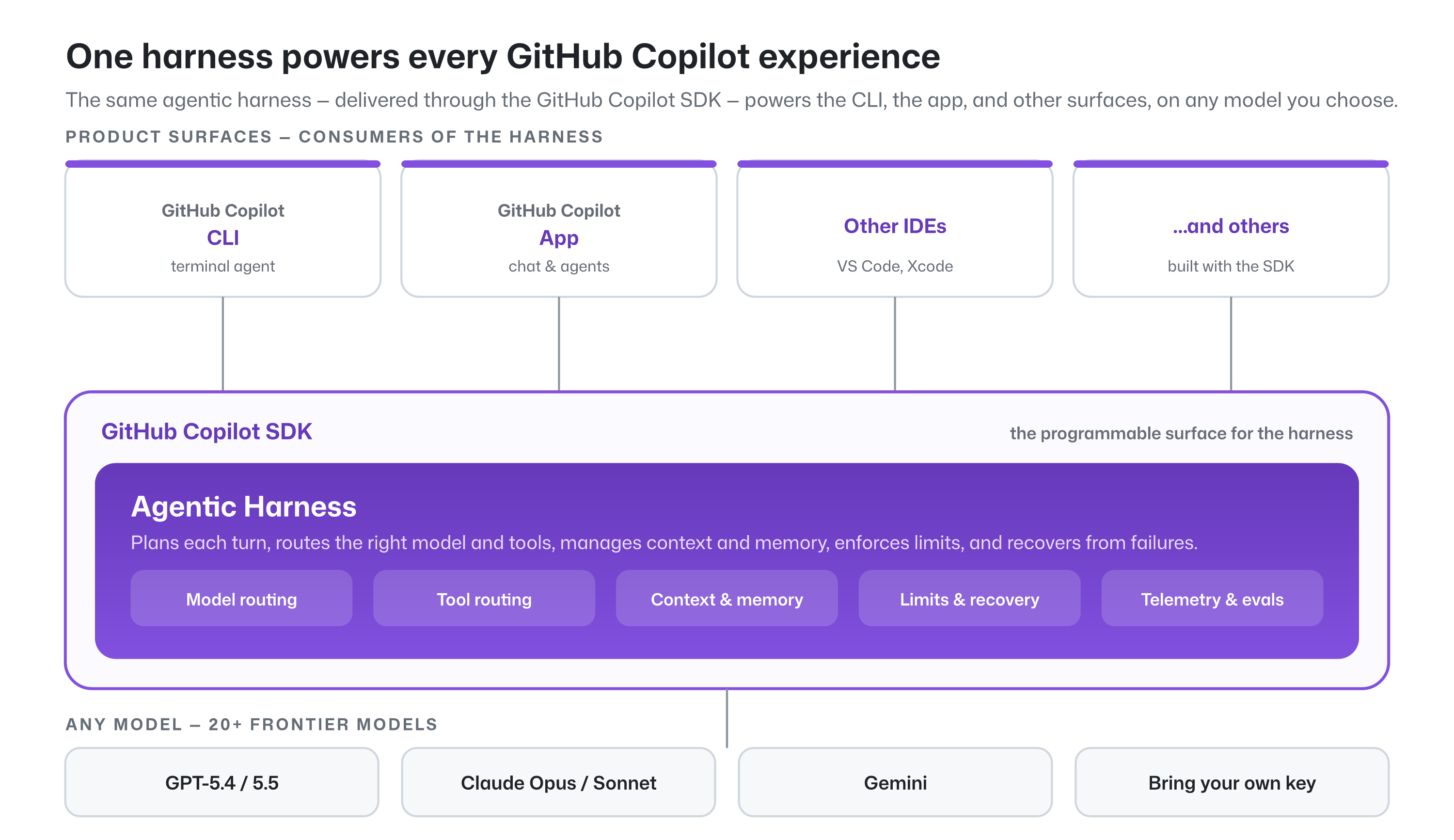
Evaluating GitHub Copilot Agentic Harness Performance Across Models and Tasks
the GitHub Copilot agentic harness delivers strong results across multiple benchmarks and leading token efficiency, while maintaining flexibility to choose among more than 20 models.
GitHub Copilot agentic harness supports integration with more than 20 distinct AI models to balance performance and token efficiency. This architectural approach demonstrates strong results across various benchmarks by providing flexibility in model selection for specific coding tasks. Developers can leverage these findings to optimize their agentic workflows by selecting models that prioritize either high-speed output or superior reasoning capabilities. The framework serves as a scalable solution for organizations aiming to maintain high performance without sacrificing operational efficiency. By evaluating different models within a unified harness, the system reduces the complexity typically associated with managing heterogeneous AI agent environments. These insights are essential for teams looking to refine their development infrastructure and improve overall coding productivity through advanced AI integration.
Source: The GitHub Blog
OpenKnowledge: Open Source AI-First Markdown Editor and Wiki
Full WYSIWYG so that editing markdown files feels like editing a Google Doc or Notion page.
OpenKnowledge is licensed under the GNU General Public License v3.0 or later (GPL-3.0-or-later).
OpenKnowledge functions as a local-first markdown editor that offers a WYSIWYG interface for managing documentation and team-based knowledge sharing. The platform features direct integrations with various LLMs, including Claude and Codex, to facilitate collaborative AI-assisted writing and agentic workflows. By utilizing a git-based backend, the tool enables no-code team synchronization and version control for markdown files. Developers can deploy the software via a macOS desktop application or run it as a local web service using the provided CLI interface. This project is released under the GPL-3.0-or-later license, allowing for community-driven contributions and custom agentic integrations through the Model Context Protocol. The architecture specifically aims to bridge the gap between traditional markdown simplicity and the advanced capabilities of modern AI coding agents.
Source: Hacker News
AI Infrastructure
This category focuses on the foundational hardware, software, and networking architectures required to power large-scale artificial intelligence models. It explores critical advancements in data centers, GPU orchestration, and specialized compute fabrics, alongside the essential implementation of privacy-preserving technologies and systematic asset classification to secure AI-native ecosystems.
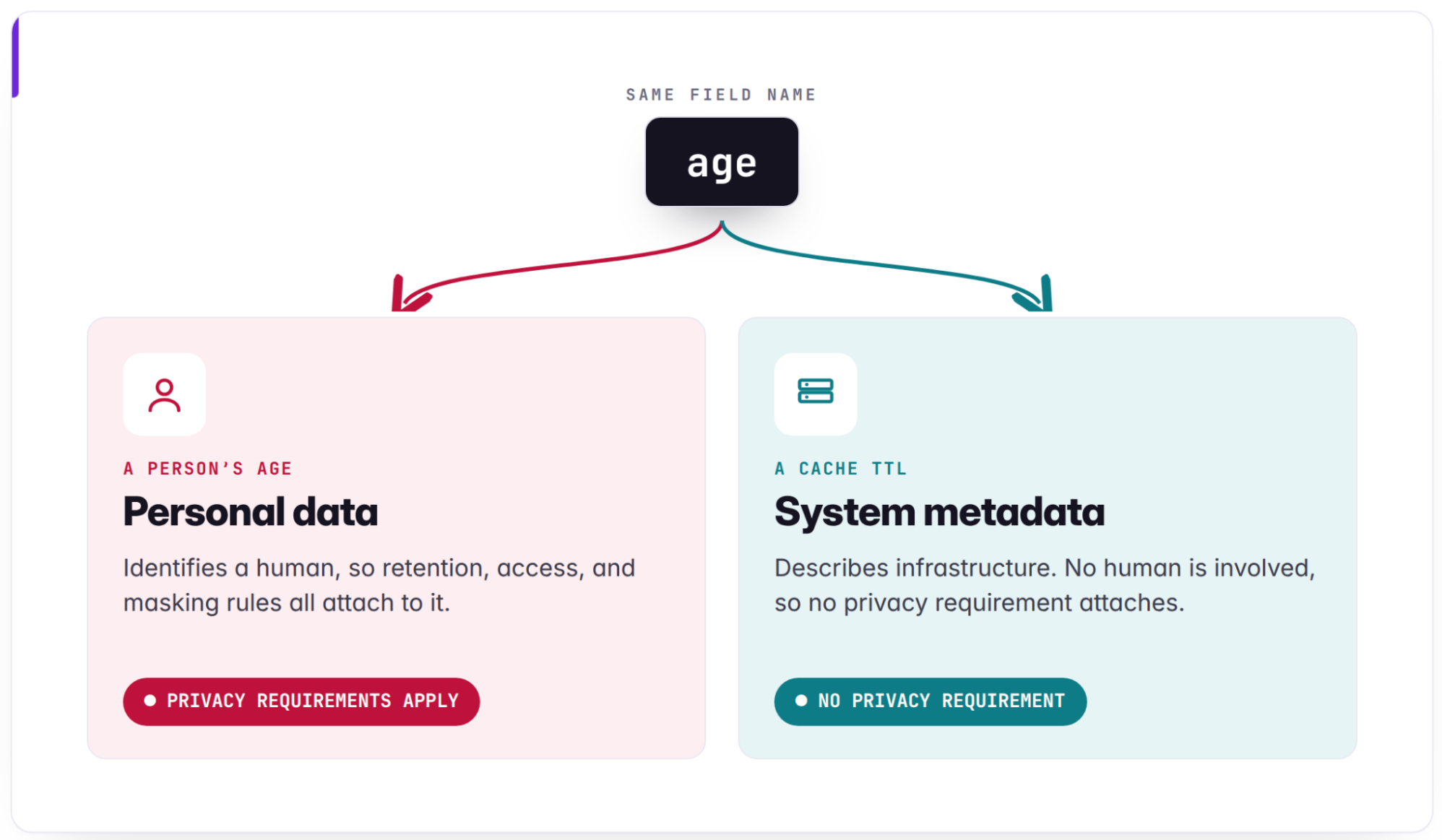
Privacy-Aware Infrastructure: Asset Classification for AI-Native Systems
Privacy controls — systems that enforce retention, access, allowed-purpose, downstream-sharing, or anonymization policies — require a reliable understanding of data to function.
This can be complex, as demonstrated by a field simply named “age“: In one context, it might [...]
Privacy controls require a reliable understanding of data to function effectively within complex AI-native infrastructure environments. Automated asset classification serves as the foundational layer for enforcing critical policies such as retention, access, and anonymization. Ambiguity in data labeling, such as varying interpretations of an "age" field, underscores the significant technical complexity inherent in modern data governance. Systems must accurately identify data attributes before any downstream security or compliance controls can be applied. Integrating these classification mechanisms allows organizations to scale their privacy frameworks without sacrificing operational agility. Robust infrastructure design now prioritizes visibility as a mandatory prerequisite for maintaining user trust and regulatory compliance in the era of large-scale AI deployment.
Source: Engineering at Meta
Foundation Models
Foundation models serve as the backbone of modern artificial intelligence, encompassing large-scale architectures trained on vast datasets to perform diverse downstream tasks. This category explores the evolving landscape of model design, including the critical technical tradeoffs between massive large language models and resource-efficient small language models. We analyze the latest advancements in scaling laws, architectural efficiency, and deployment strategies that define the next generation of generative AI capabilities.
Large Language Models vs. Small Language Models: Design and Tradeoffs
In this article, we will explore those constraints through three layers of model design, look at the tradeoffs that come with each approach, and investigate the production systems that combine both small and large models.
Small language models offer distinct operational advantages by reducing memory and computational overhead compared to their massive counterparts. Strategic model deployment often involves balancing the limitations inherent in each architecture to optimize performance for specific production tasks. Design philosophies shift significantly when choosing between the raw capability of massive parameters and the efficiency of compact, task-specific models. Many modern production systems successfully implement hybrid architectures that leverage the specialized strengths of both model sizes to maximize output quality while minimizing infrastructure costs. Mastering these tradeoffs allows developers to deploy robust AI solutions that perform reliably across varied environmental constraints and resource availability levels. Careful evaluation of model depth and breadth remains essential for scaling intelligent applications effectively in resource-constrained enterprise environments.
Source: ByteByteGo Newsletter
Data & Analytics
Explore the latest advancements in data management, processing, and analytical insights. From the evolution of cloud-native databases like MongoDB Atlas to the emerging role of structured and unstructured data in powering modern AI applications, this section covers the tools and strategies that define the data-driven landscape. Stay informed on how infrastructure scales to meet the growing demands of real-time intelligence.
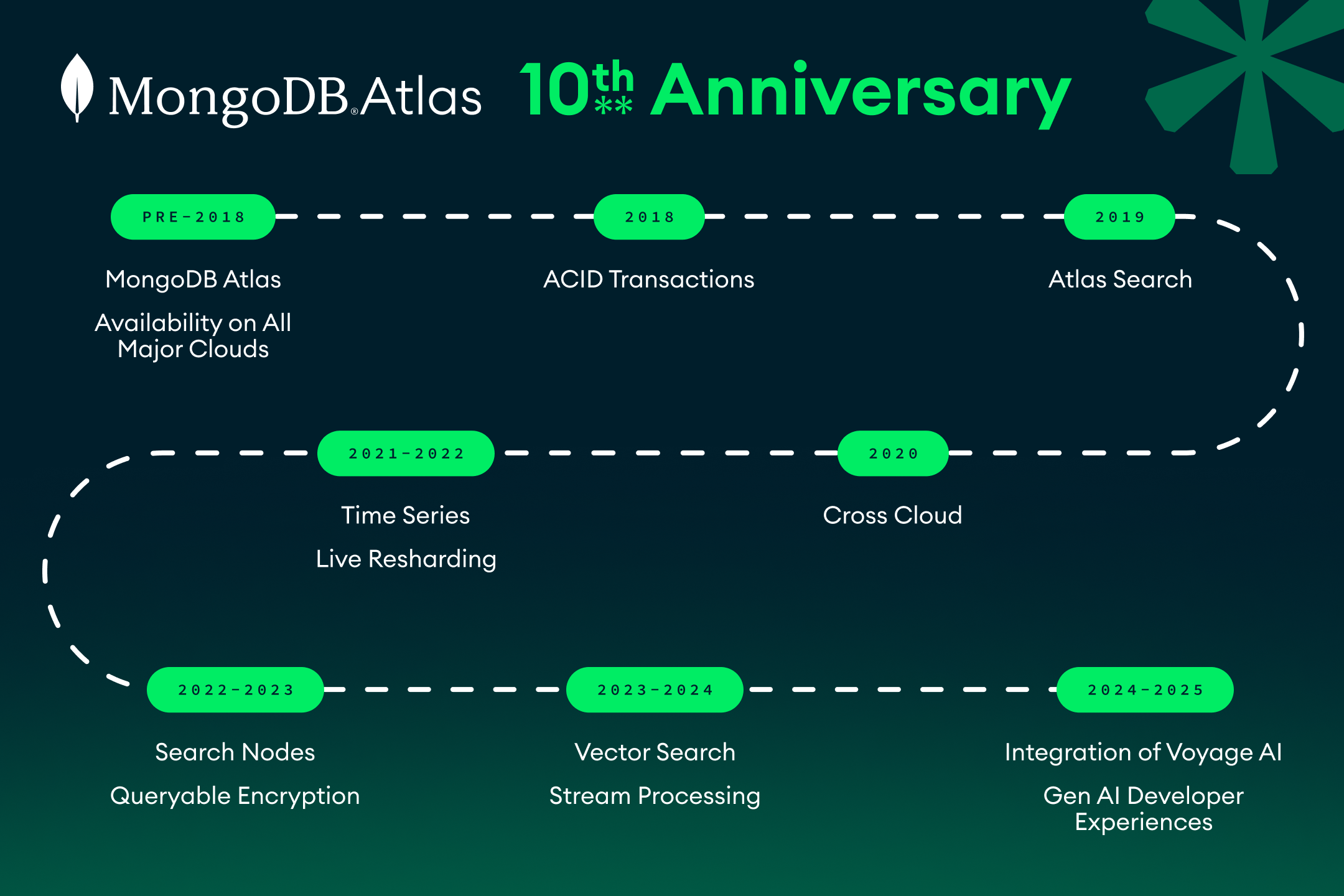
10 Years of MongoDB Atlas: Scaling Data for the AI Era
Atlas serves more than three trillion queries a day (a roughly threefold increase just since 2023!), and represents 75% of MongoDB’s revenue.
Today, more than 250,000 builders get started on Atlas every month.
MongoDB Atlas now handles more than three trillion queries per day, marking a significant milestone in its ten-year evolution from a cloud-based database service to a comprehensive data platform. Initially launched to provide developers with a reliable, cloud-native experience for MongoDB, the service has become a critical component of modern software architecture. The platform currently supports over 250,000 active builders every month, accounting for 75% of the company's total revenue. As enterprises increasingly transition to multi-cloud environments, Atlas has evolved to provide the necessary flexibility and operational simplicity required to manage complex data workflows. By integrating core features like real-time retrieval and search, the platform is now positioning itself as a foundational layer for building scalable, production-ready AI applications. This strategic shift underscores the growing demand for durable data platforms that can handle the increased complexity and performance requirements inherent in modern generative AI deployments.
Source: MongoDB Blog
AI Applications
Explore the rapidly evolving landscape of AI-driven tools and intelligent agents designed to streamline workflows and boost productivity. This category highlights innovative software that leverages personal data and machine learning to deliver tailored, context-aware solutions for both individuals and businesses. Stay informed on the latest breakthroughs in practical AI deployment and the transformative technologies shaping the next generation of digital assistance.
Zaro: Build AI Agents and Apps Using Personal Contextual Data
Build agents & apps on top of your context with one prompt.
Zaro pulls it into one place and lets you build apps from it in minutes: your research, your side projects, your plans, your decisions.
Zaro integrates data from siloed sources including Gmail, Slack, notes, and browser tabs to automate software development through a single prompt. This platform functions by pulling scattered information into a centralized hub, enabling users to transform research, projects, and plans into functional applications within minutes. The tool automatically maintains these apps by syncing with connected data sources daily, ensuring information remains current without manual intervention. By removing the need for traditional coding or long-term maintenance, the service aims to solve the problem of abandoned prototypes and fragmented digital workspaces. Users can effectively turn their personal or professional knowledge base into a self-updating digital environment through the system's no-code interface. This approach streamlines complex workflows by bridging the gap between disconnected communication channels and actionable software solutions.
Source: Product Hunt
This report is auto-generated by WindFlash AI based on public AI news from the past 48 hours.