Wednesday, May 27, 2026 · 10 curated articles

Editor's Picks
Today’s updates represent a jarring collision between the 'Bitter Lesson' of scaling and the 'Cold Reality' of production engineering. On one hand, we see the sheer force of compute-led discovery: Anthropic’s Claude Opus 4.8 is crushing agentic benchmarks like Online-Mind2Web, while BioHub’s ESMFold2 proves that general-purpose transformer architectures can out-predict specialized biological models by simply ingesting more sequence data. We are effectively watching the 'programmable biology' and 'autonomous computer-use' domains move from experimental to viable. When a model like Opus 4.8 surpasses the 10% all-pass mark on the Legal Agent Benchmark, it signals that we aren’t just building better chatbots; we are building reliable cognitive engines for high-stakes workflows.
However, the 'ITBench-AA' results serve as a necessary bucket of cold water. Even our frontier models—including the new Opus 4.8 and GPT-5.5—are still failing more than half the time when tasked with real-world Site Reliability Engineering (SRE). This gap reveals a fundamental flaw in current agentic design: 'over-investigation.' As the benchmark data suggests, models often confuse symptoms for root causes. For developers, the takeaway is clear: autonomous agents are currently better at 'doing' (executing tasks) than 'diagnosing' (reasoning through causality in complex systems). We are in the 'mid-transition' phase where the UI/UX of agentic workflows is ahead of their underlying reasoning precision.
This leads us to the most critical cultural shift mentioned today: 'The VibeSec Reckoning.' The era of 'vibe coding'—where developers trust AI-generated code because it 'looks right'—is officially over. With 25% of AI-generated code containing vulnerabilities, we can no longer treat LLM outputs as a harmless productivity boost. This is why the industry is shifting toward 'secure-by-default' harnesses and deterministic checks. AI is an extension of human intelligence, but as today’s research highlights, it lacks the lived experience to self-correct based on physical reality. It only knows the 'linguistic sediment' of our knowledge.
Finally, the shift to usage-based pricing by OpenAI and Anthropic is the final sign that the subsidized 'honeymoon phase' of AI development is ending. When you combine the higher costs of frontier models with the necessity of defensive infrastructure, the unit economics of AI become a board-level concern. Engineers must now optimize for 'token efficiency' as much as they do for 'latency.' The path forward isn't just bigger models; it's the integration of Databricks-style operational data feeds and Airtable-like semantic search layers to ensure that every expensive token spent is grounded in the most relevant, secure, and governed data available.
Foundation Models
Foundation models continue to redefine the boundaries of artificial intelligence through significant architectural improvements and enhanced reasoning capabilities. Recent updates from industry leaders like Anthropic demonstrate a shift toward dynamic workflows that optimize performance across rigorous technical benchmarks. These advancements are essential for enterprises and developers seeking to integrate robust, scalable AI solutions into core operations while maintaining high accuracy and efficiency in complex, domain-specific tasks.
Anthropic Launches Claude Opus 4.8 with Improved Benchmarks and Dynamic Workflows
Claude Opus 4.8 is the strongest computer-use and browser-agent model we’ve tested, scoring 84% on Online-Mind2Web
fast mode for Opus 4.8—where the model can work at 2.5× the speed—is now three times cheaper than it was for previous models.
Claude Opus 4.8 achieves an 84% score on the Online-Mind2Web benchmark for computer-use tasks, significantly outperforming its predecessor and competitors like GPT-5.5. The updated model introduces a new fast mode that operates at 2.5 times the speed while reducing costs by three times compared to previous iterations. Users on the Claude interface now benefit from granular control over computational effort, while Claude Code gains dynamic workflows for managing large-scale engineering problems. In specialized evaluations, the model became the first to surpass the 10% all-pass standard on the Legal Agent Benchmark, reflecting its enhanced reliability in complex, high-stakes environments. Early enterprise testers report that Opus 4.8 demonstrates superior judgment and context retention, particularly when executing autonomous agentic workflows or tool-calling sequences. This release maintains the existing pricing structure of the Opus line, ensuring that higher intelligence remains accessible at a competitive cost.
Source: Anthropic News
Research
Explore the cutting edge of scientific discovery and theoretical frameworks shaping the future of technology. From breakthrough protein folding models like ESMFold2 to philosophical inquiries into how AI augments human cognition, this section highlights pivotal studies from leading global labs. These research papers provide the foundational insights necessary to understand the complex interplay between artificial intelligence, biological systems, and the future of human intelligence.
ESMFold2: BioHub’s Open Scientific Engine for Protein Prediction and Design
ESMFold2 reports state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics
they are also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures
BioHub has announced ESMFold2, an open scientific engine designed to power prediction, design, and discovery across protein biology using a dataset of 6.8 billion proteins and 1.1 billion predicted structures. This new model demonstrates state-of-the-art performance on protein interactions and antibody design, outperforming specialized models like AlphaFold3 on several challenging protein-related problems. By leveraging vanilla BERT-like transformer architectures trained on massive, diverse datasets, the team has validated the "Bitter Lesson" in biology, proving that scaling laws can overcome the need for traditional inductive biases like multi-sequence alignments. The release includes evidence of inference-time scaling working across targets in cancer and immunology, alongside a comprehensive protein atlas for researchers. This approach signifies a shift toward programmable biology where general-purpose models learn complex biological structures and functions purely through massive compute and sequence data.
Source: Latent Space
Extending Human Intelligence Through AI: A Research Perspective
Modern AI systems are powerful not because they replicate human intelligence, but because they presuppose it
AI safety is a system-level challenge, shifting attention from “rogue AI” narratives toward harnessing engineering and governance.
Modern AI systems derive their power by extending structures already present in human cognition and language rather than replicating human intelligence independently. These systems learn statistical relationships within a linguistic world that contains sedimented structures of human understanding, which explains their fluency alongside recurring boundaries like hallucinations. While humans remain answerable to the world through lived experience that corrects beliefs, AI models extend patterns within text and lack this direct corrective feedback loop. Research suggests that AI safety should be addressed as a system-level engineering and governance challenge instead of focusing on hypothetical rogue AI narratives. This phenomenological approach, drawing on the work of Edmund Husserl, shifts the focus toward building trustworthy systems grounded in human intelligence. By framing AI as an extension of natural intelligence, researchers can better understand why models struggle with compositional reasoning and tracking changes that are intuitive to humans.
Source: Microsoft Research Blog

AI Business
AI Business tracks the commercial evolution and monetization strategies of the artificial intelligence sector. As industry leaders like OpenAI and Anthropic achieve product-market fit, the focus is shifting toward usage-based pricing and sustainable revenue models for enterprise-grade solutions. This category examines how companies navigate the transition from experimental development to scalable, profitable operations in a competitive global market.
Anthropic and OpenAI Shift to Usage-Based Pricing After Achieving Product-Market Fit
April saw both leading model companies release new frontier models with a higher API price
updated Codex pricing to align with API token usage, instead of per-message pricing.
Anthropic and OpenAI have transitioned their enterprise pricing models from flat-rate seat subscriptions to usage-based API pricing, signaling a significant shift toward profitability and product-market fit. Personal subscribers currently paying $200 monthly for premium plans can generate token usage valued at over $2,180 at standard API rates, revealing the extent of subsidies previously provided to heavy users. Anthropic officially moved its Enterprise plan to a base fee plus API usage model in late 2025, while OpenAI realigned Codex and ChatGPT Enterprise pricing with token usage throughout April 2026. This strategic pricing change coincides with the release of frontier models like GPT-5.5 and Opus 4.7, which carry higher costs but target high-value enterprise workflows like coding agents. The move suggests that leading AI labs are prioritizing revenue sustainability and preparing for potential public offerings by monetizing their most successful agent-based products.
Source: Simon Willison's Weblog
AI Agents
AI agents are evolving from simple chatbots into specialized autonomous assistants capable of handling complex enterprise tasks, though significant performance gaps remain in demanding domains like IT operations. Recent developments highlight the introduction of rigorous benchmarks like ITBench-AA to evaluate these models, alongside real-world applications such as AWS's NarrateAI, which integrates agentic workflows into business intelligence. These advancements signal a shift toward more reliable, goal-oriented systems that bridge the gap between foundation models and practical industrial problem-solving.
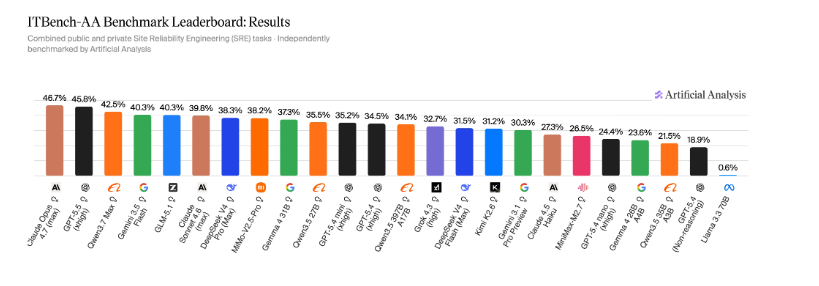
ITBench-AA: Frontier Models Score Below 50% on New Enterprise IT Benchmark
All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite.
Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%.
Frontier AI models currently score below 50% on the newly launched ITBench-AA, the first benchmark dedicated to agentic enterprise IT tasks developed by Artificial Analysis and IBM. Claude Opus 4.7 leads the initial evaluation at 47% accuracy, followed by GPT-5.5 at 46% and Qwen3.7 Max at 42%, highlighting a significant performance gap in handling complex Site Reliability Engineering (SRE) tasks. The benchmark requires models to diagnose live Kubernetes incidents by analyzing logs, traces, and application topologies to identify specific root-cause entities within a sandboxed environment. Among open-weights models, GLM-5.1 leads with a 40% score, effectively matching the performance of Gemini 3.5 Flash while outperforming Gemini 3.1 Pro Preview. Evaluation data reveals that longer task trajectories do not necessarily correlate with higher accuracy, as models that over-investigate often misidentify upstream fault mechanisms or symptoms as primary root causes.
Source: Hugging Face Blog
AWS SMGS Uses Amazon Bedrock AgentCore to Transform BI with NarrateAI Assistant
NarrateAI, our intelligent conversational solution, addresses this through conversational agentic AI powered by our data lake and Amazon Bedrock AgentCore.
Amazon Bedrock AgentCore removed the need to build custom orchestration infrastructure, providing serverless architecture, built-in authentication
NarrateAI utilizes a two-layer architecture separating batch narrative generation from real-time interaction to provide on-demand business intelligence for the AWS Sales, Marketing and Global Services organization. Amazon Bedrock AgentCore enabled the deployment of this intelligent conversational solution in weeks rather than months by providing serverless architecture and built-in memory management. The system addresses traditional business intelligence bottlenecks where leaders previously lost hours manually gathering data from fragmented sources and static dashboards. Specialized AI agents now handle intelligent routing and validation, allowing leaders from the CEO to field personnel to ask natural language questions about performance metrics. This approach removes the need for custom orchestration infrastructure while maintaining contextually accurate responses across complex data hierarchies. By integrating with a data lake and the Amazon Quick interface, NarrateAI transforms raw data into actionable insights for time-sensitive global operations.
Source: AWS Machine Learning Blog

AI Infrastructure
This category explores the underlying frameworks and hardware essential for powering modern artificial intelligence applications. We cover the evolution of scalable search layers, vector databases, and specialized compute resources that enable developers to integrate semantic capabilities into complex data ecosystems. By focusing on the structural components behind the models, we provide insights into how leading platforms maintain performance and reliability while deploying resource-intensive AI features at scale.
How Airtable Built a Scalable Search Layer for Semantic AI Features
roughly three-quarters of them sit completely idle. This fact, more than any algorithm or vendor choice, decided the architecture
Queries had to return within 500 milliseconds at the 99th percentile
Airtable handles embeddings for hundreds of thousands of customer databases where roughly 75% of them remain completely idle during any given week. This specific data characteristic forced an engineering architecture prioritized for multi-tenancy and horizontal scaling rather than a standard vector database selection. The system powers the Omni natural-language interface and linked record recommendations by retrieving semantically relevant rows from bases containing up to 500,000 rows. To ensure a seamless user experience, the infrastructure team established a performance requirement where 99% of queries return within 500 milliseconds. Key design constraints included maintaining high-throughput writes for constant data changes and ensuring all components are self-hosted to protect customer data privacy. This specialized search layer enables large language models to process relevant context efficiently without exceeding token limits or incurring excessive costs.
Source: ByteByteGo Newsletter
Data & Analytics
Data & Analytics focuses on the evolving landscape of big data processing, business intelligence, and real-time insights. This sector is witnessing a shift toward unified lakehouse architectures and seamless data integration, as exemplified by recent advancements in change data capture and operational workflows. Organizations are increasingly leveraging these tools to bridge the gap between raw data storage and actionable intelligence, ensuring high-performance analytics across diverse enterprise environments.
Databricks Announces Lakebase Change Data Feed (CDF) for Operational Data
Lakebase features a Change Data Feed (CDF) that is stored and governed in Unity Catalog Managed Tables.
Your operational database is now your native Bronze layer, eliminating the need for separate pipelines or extraction jobs to land data into the Lakehouse.
Databricks has launched the Public Preview of Lakebase Change Data Feed (CDF), enabling teams to store and govern operational database changes directly in Unity Catalog Managed Tables. This native feature eliminates the traditional O(n) human effort required to configure and monitor separate extraction pipelines for individual data sources and destinations. By treating the operational database as the native Bronze layer within a medallion architecture, users can now subscribe to a single feed for streaming pipelines, materialized views, and embedding generation. The system ensures complete isolation from primary operational workloads while maintaining full data governance and lineage across the entire life cycle through Unity Catalog. This integration bridges the gap between OLTP databases and the Lakehouse, allowing agents and models to read data directly without manual replication friction. Consequently, organizations can maintain complex data branches more sustainably in agent-first development environments while leveraging open formats like Apache Iceberg and Delta Lake.
Source: Databricks
Developer Tools
The landscape of developer tools is undergoing a radical shift as AI-accelerated workflows become the industry standard, necessitating a new focus on security and reliability. As VibeSec challenges emerge, developers must balance the unprecedented speed of automated code generation with robust verification frameworks and proactive threat detection. This section explores the latest innovations in IDEs, CI/CD pipelines, and security suites designed to fortify the modern software supply chain against AI-specific vulnerabilities.
The VibeSec Reckoning: Securing AI-Accelerated Development
AI agents frequently recommend insecure configurations, creating security problems.
AI-generated code with confirmed vulnerabilities25%
AI-generated code currently results in confirmed vulnerabilities in approximately 25% of cases, highlighting a systemic risk in the rapid adoption of "vibe coding" practices. While AI agents significantly accelerate software prototyping for non-technical builders, they frequently prioritize the path of least resistance over secure configurations. Common security failures identified during production scaling include AI recommendations for public storage access and the granting of excessive token permissions that could allow lateral movement through cloud workspaces. To mitigate these risks, engineering teams must implement security context files to guide AI behavior and provide builders with secure-by-default harnesses and templates. Furthermore, human judgment remains essential for validating AI output through deterministic checks in the development workflow to prevent the leakage of sensitive assets or secrets. Establishing a daily security intelligence feed can also help organizations stay ahead of the rising tide of attacks exploiting application vulnerabilities.
Source: Martin Fowler

AI Applications
Artificial intelligence is rapidly evolving from experimental frameworks into specialized tools that address real-world challenges across sectors like cybersecurity, finance, and healthcare. These applications leverage machine learning and automation to identify complex patterns, streamline remediation processes, and significantly reduce human intervention in critical operations. By integrating AI into specialized workflows, organizations are not only enhancing their defensive capabilities but also unlocking new levels of operational efficiency and precision in an increasingly data-driven landscape.
Google Launches AI Threat Defense to Automate Cybersecurity and Remediation
Google AI Threat Defense fuses the reasoning power of Gemini and other frontier models, the contextual risk prioritization of Wiz
Our secure-by-default architecture automatically blocks 10 million spam emails every minute, and protects billions of users and customers
Google AI Threat Defense integrates Gemini's reasoning capabilities with Wiz's risk prioritization and CodeMender's remediation tools to automate defense against high-speed, AI-powered cyber threats. This automated security system addresses a shifting landscape where cybercriminals use AI to exploit vulnerabilities in hours rather than weeks, rendering manual defense methods obsolete. The platform leverages Mandiant's frontline expertise and Google's secure-by-default architecture, which currently blocks 10 million spam emails per minute. By utilizing a collection of models for multiple analysis passes, the solution identifies, prioritizes, and patches vulnerabilities before they can be exploited. The implementation follows a structured four-step framework: prepare, scan and prioritize, remediate, and monitor. This launch marks a significant evolution in enterprise security, transforming vulnerability management into a machine-speed operation that grants defenders a distinct advantage over increasingly sophisticated adversaries.
Source: Google Cloud Blog

This report is auto-generated by WindFlash AI based on public AI news from the past 48 hours.