2026-06-29 · AI Strategy
今天最值得写的 AI 话题,不是哪个模型又快了一点,哪个工具又能多生成几行代码。
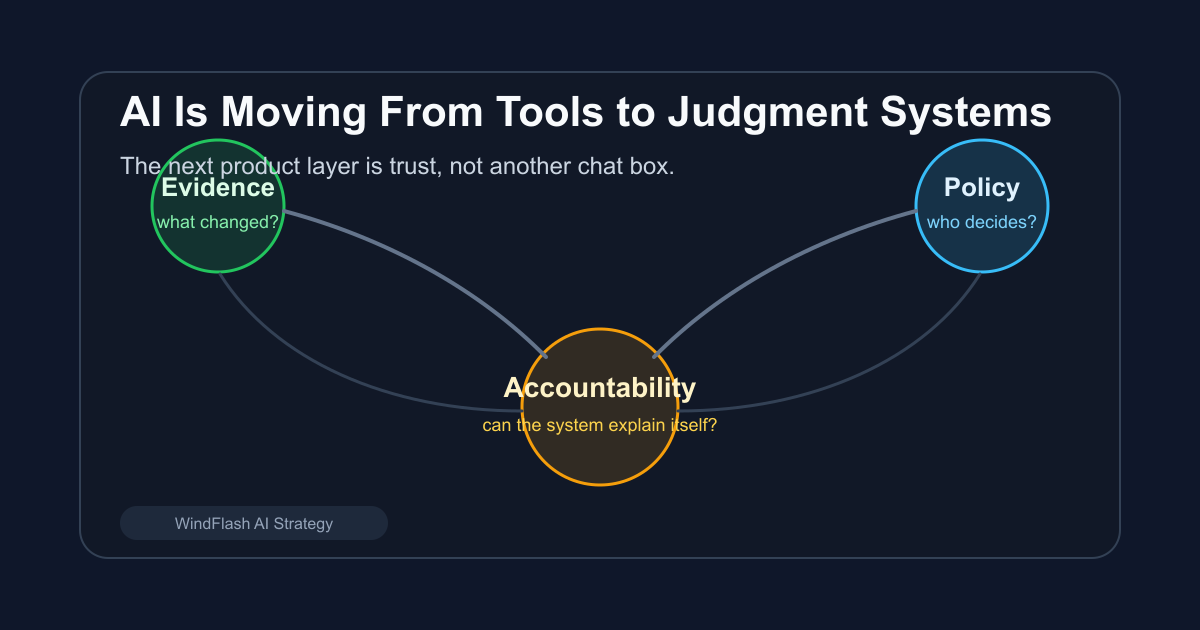
真正值得注意的是:AI 正在进入那些“答错了会有后果”的场景。
有人用 Claude 给自己的 MRI 做第二意见。大学教授发现大规模 AI 作弊。欧洲关于聊天扫描的争议继续发酵。新的多模态安全护栏开始把安全策略当成运行时输入。GLM 5.2 在一个安全基准里超过 Claude Code,但专门设计的安全流水线仍然更强。
这些事情看起来分散,其实指向同一个变化:
AI 正在从帮我们产出内容的工具,变成参与判断的系统。
这会彻底改变 AI 产品的标准。
过去的问题是:它能不能完成任务?

第一波 AI 产品主要看输出。
能不能写邮件?能不能总结 PDF?能不能生成代码?能不能画图?能不能回答客服问题?
这是自然的起点。输出很容易判断。用户看一眼,就知道文案有没有用,图片好不好看,代码能不能跑,摘要有没有抓住重点。
但下一波不一样。
问题不再只是:
模型能不能生成一个东西?
而是:
这个系统能不能被放进一次真实判断里?
这就是更高的产品标准。
当 AI 参与医疗第二意见时,问题不只是它说得流不流畅,而是它能不能展示证据、不确定性、边界和升级路径。当 AI 进入教育时,问题不只是学生能不能写出更好的答案,而是学校还能不能定义作者身份、考试公平和评价方式。当 AI 进入安全检测时,问题不只是模型能不能发现漏洞,而是工作流能不能把模型能力和验证机制分开看。
所以,“模型更强”已经不是完整的产品策略了。
Claude 看 MRI 的故事,本质是证据问题
Claude 看 MRI 的故事之所以有冲击力,是因为它非常具体。
在原文里,作者用 Claude Opus 4.8 分析自己的肩部 MRI 文件,发现模型结论和医生报告出现了直接冲突:医生判断有 Grade III 部分厚度撕裂,而 Opus 报告肌腱完整。
这不代表 AI 一定对。
也不代表医生一定错。
真正重要的是:普通人现在可以对复杂医学数据做一次看起来很严肃的二次分析。患者带着 AI 生成的证据、问题和怀疑进入诊疗关系,这会改变医疗体验本身。
对产品开发者来说,教训很直接:
如果你的 AI 产品进入高信任场景,输出不能单独存在。
它必须回答:
- 它用了哪些证据?
- 它忽略了什么?
- 它有多确定?
- 什么信息会改变它的结论?
- 什么时候必须交给专家?
一个只给出自信结论的 AI 医疗助手是危险的。一个能展示相关影像、解释不确定性、建议专业复核的 AI 医疗助手,是完全不同的产品。
区别不只在模型质量。
区别在责任设计。
SingGuard 说明安全产品会怎么演进
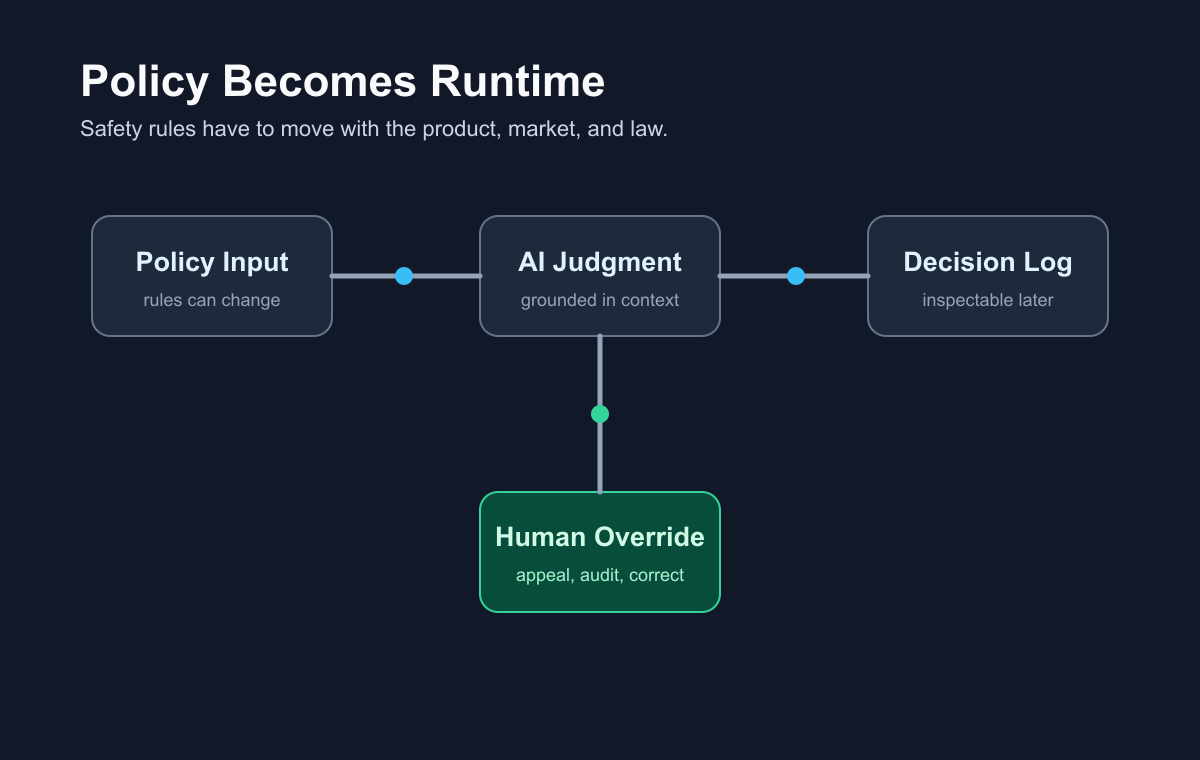
静态审核越来越不够用了。
这也是 SingGuard 值得关注的原因。它把当前安全策略当成运行时输入,逐条规则做基于策略的判断。它的基准包含 56340 个样本,覆盖 80 多种细粒度风险类型。
这件事重要,是因为真实世界的规则会变。
公司规则会变。当地法律会变。平台规范会变。医疗助手、游戏聊天、教育产品、安全助手、客服系统,它们需要的边界都不一样。
旧的产品模型是:
做一个过滤器,发布出去,偶尔调一调。
新的产品模型是:
把策略本身当成运行时系统的一部分。
这意味着,好的 AI 安全工具会越来越像一个操作层,而不是单个分类器:
- 策略输入
- 证据抽取
- 逐条规则推理
- 决策日志
- 申诉和覆盖机制
- 面向新规则的持续评估
安全也会从后台能力,变成用户能感知的产品表面。
用户不仅想知道模型回答了什么,也会想知道是哪条规则影响了这个回答。
EU Chat Control 是同一个问题的政策镜像
欧盟关于 Chat Control 的争议,展示的是另一面:当制度面对技术风险时,很容易把答案推向监控。
在 Patrick Breyer 的文章里,核心担忧是私人通信可能在不够透明的政治协商中,被推向更广泛的扫描要求。
无论你是否同意文章里的每个判断,这里的产品教训都很清楚:一旦技术让某种检测成为可能,制度就会想把这种能力变成义务。
这会让产品团队处在一个很微妙的位置。
同样的 AI 技术,可以用来识别伤害,也可以让大规模扫描变得正常化。同样的安全基础设施,可以降低风险,也可能变成控制层。同样的审计记录,可以创造责任,也可能变成监控记录。
所以问题不能只是:
我们能不能检测出来?
更好的问题是:
这个检测系统创造了什么权力?谁能使用这种权力?
这时候,隐私保护、最小化收集、本地处理、明确授权、透明治理,就不再是政策口号,而是产品架构。
教育是最早响起的警报
布朗大学 AI 作弊事件不只是学生滥用 AI。
它暴露的是:很多教育评价制度的前提正在失效。
传统考试默认学生资源有限、个人独立完成、作者身份大致可观察。AI 同时冲击这三点。如果学生随时都能生成高质量推理,学校就必须决定:禁止、检测、重做考试,还是把 AI 纳入制度。
多数机构可能会四件事一起做。
但这个问题不只属于教育。
任何建立在“专业能力稀缺”上的工作流,都会被 AI 的能力供给冲击:
- 法律草拟
- 医疗分诊
- 软件审查
- 金融分析
- 学术写作
- 合规工作
旧的门槛不会一夜消失,但它们必须重新解释自己为什么存在。
这会给一类产品创造机会:不是单纯抓违规,而是帮助机构重新设计评价方式。
GLM 5.2 提醒我们:裸模型能力不够
Semgrep 的安全基准很适合作为提醒。
在 Semgrep 的测试文章里,GLM 5.2 在纯提示词设置下,IDOR 检测分数高于 Claude Code,而且每个漏洞发现成本更低。但 Semgrep 自己的专门安全流水线,表现仍然强过两种裸模型方案。
这就是接下来会反复出现的模式。
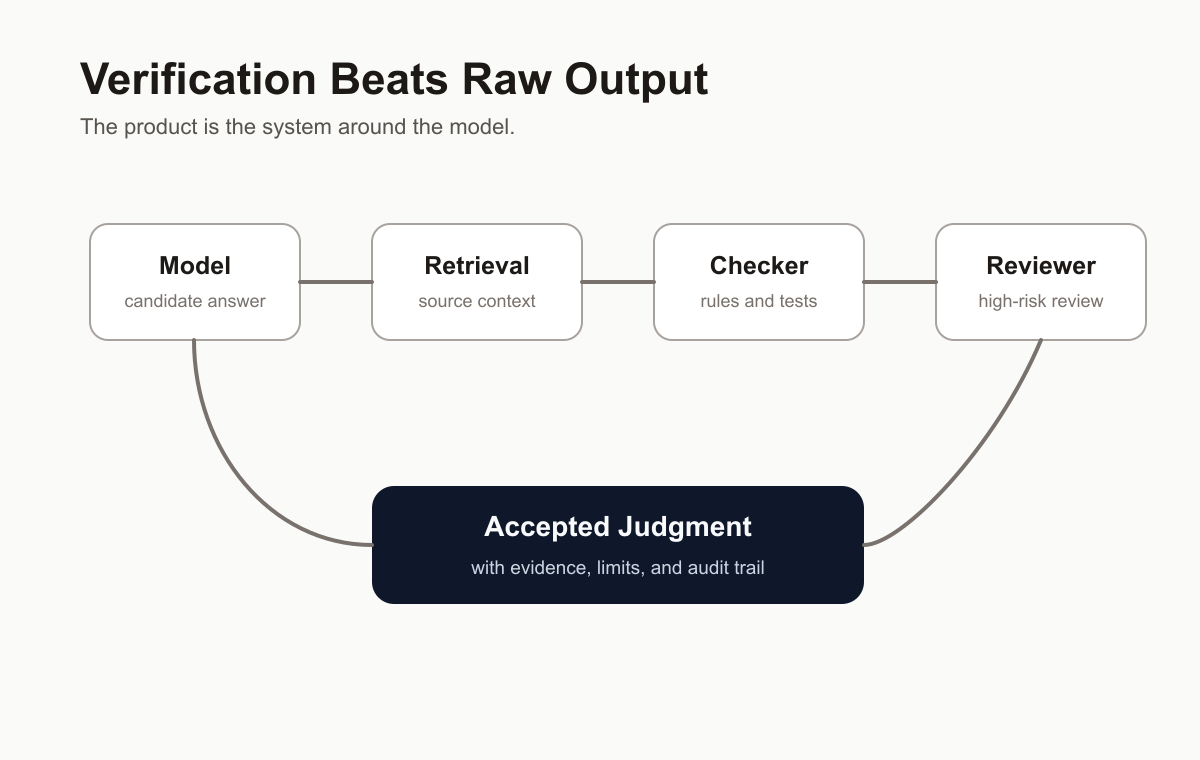
真实产品里,胜出的通常不是“单个最强模型”。
而是模型加上:
- 检索
- 任务框架
- 结构化输出
- 验证器
- 领域规则
- 人工复核
- 成本控制
在需要判断的工作里尤其如此。便宜的开源权重模型可能适合某一层。更强模型可以负责升级处理。确定性检查器可能比两者都重要。最后一步仍然可能需要人。
产品不是模型。
产品是系统。
下一层 AI 产品能力,是信任
对创业者和开发者来说,结论不是空泛地“加强治理”。
真正要做的是:把信任设计成产品的一层。
一个严肃的 AI 判断产品,至少应该展示五件事:
1. 证据
答案来自哪个来源、文件、图片、日志或原文?
2. 边界
系统能决定什么?什么必须升级给人?
3. 不确定性
哪些信息会让系统降低信心?
4. 策略
是哪条规则、标准或流程影响了判断?
5. 责任
谁能检查、覆盖、申诉或审计这个结果?
这不会让产品变慢。做得好,它会让产品进入更严肃的使用场景。
AI 产品的未来,不只是更好的答案。
而是能承担责任的答案。
来源
- Using Claude to get a second opinion on my MRI
- SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
- Double threat to private communications: Chat Control backroom deals
- AI fraud at Brown University: academic integrity is at risk
- GLM 5.2 beats Claude in Semgrep cybersecurity benchmarks
- WindFlash AI 技术日报:2026-06-29